文章列表
-
- Django結合使用Scrapy爬取數(shù)據(jù)入庫的方法示例
- 在django項目根目錄位置創(chuàng)建scrapy項目,django_12是django項目,ABCkg是scrapy爬蟲項目,app1是django的子應用2.在Scrapy的settings.py中加入以下代碼import osimport syssys.path.append(os.path.dir...
- 日期:2024-09-11
- 瀏覽:47
- 標簽: Django

-
- Python Scrapy多頁數(shù)據(jù)爬取實現(xiàn)過程解析
- 1.先指定通用模板url = ’https://www.qiushibaike.com/text/page/%d/’#通用的url模板pageNum = 12.對parse方法遞歸處理parse第一次調(diào)用表示的是用來解析第一頁對應頁面中的數(shù)據(jù)對后面的頁碼的數(shù)據(jù)要進行手動發(fā)送if self.pageN...
- 日期:2022-07-21
- 瀏覽:135
-
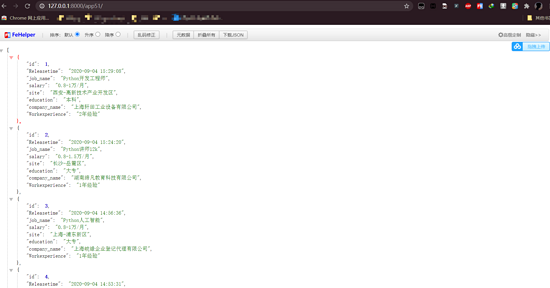
- Django-Scrapy生成后端json接口的方法示例
- 網(wǎng)上的關于django-scrapy的介紹比較少,該博客只在本人查資料的過程中學習的,如果不對之處,希望指出改正;以后的博客可能不會再出關于django相關的點;人心太浮躁,個人深度不夠,只學習了一些皮毛,后面博客只求精,不求多;希望能堅持下來。加油!學習點: 實現(xiàn)效果 django與scrap...
- 日期:2024-05-27
- 瀏覽:89
- 標簽: JavaScript
-
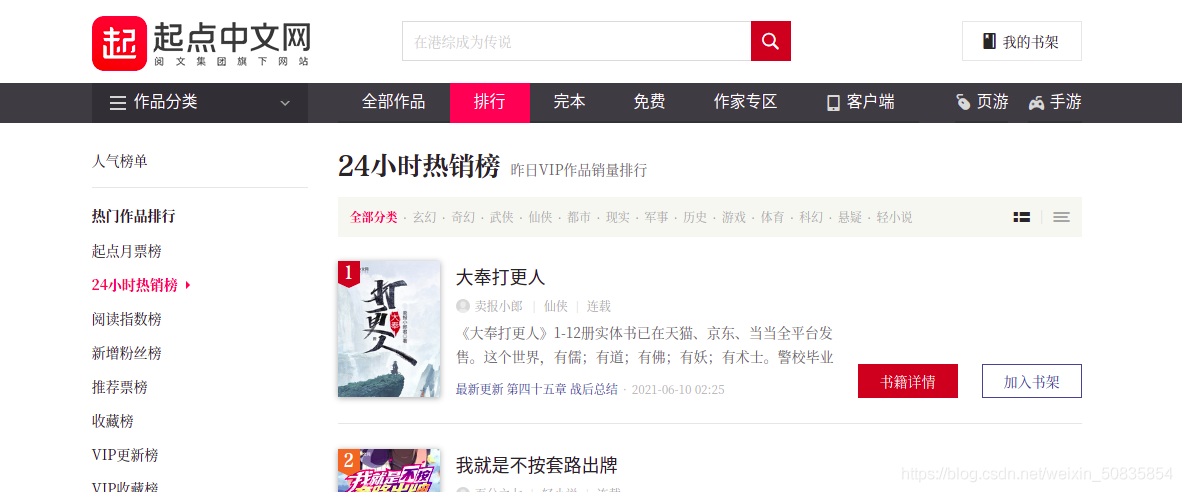
- Python scrapy爬取起點中文網(wǎng)小說榜單
- 一、項目需求爬取排行榜小說的作者,書名,分類以及完結或連載二、項目分析目標url:“https://www.qidian.com/rank/hotsales?style=1&page=1”通過控制臺搜索發(fā)現(xiàn)相應信息均存在于html靜態(tài)網(wǎng)頁中,所以此次爬蟲難度較低。通過控制臺觀察發(fā)現(xiàn),...
- 日期:2022-06-16
- 瀏覽:5

-
- python scrapy簡單模擬登錄的代碼分析
- 1、requests模塊。直接攜帶cookies請求頁面。找到url,發(fā)送post請求存儲cookie。2、selenium(瀏覽器自動處理cookie)。找到相應的input標簽,輸入文本,點擊登錄。3、scrapy直接帶cookies。找到url,發(fā)送post請求存儲cookie。# -*- c...
- 日期:2022-06-14
- 瀏覽:90
-
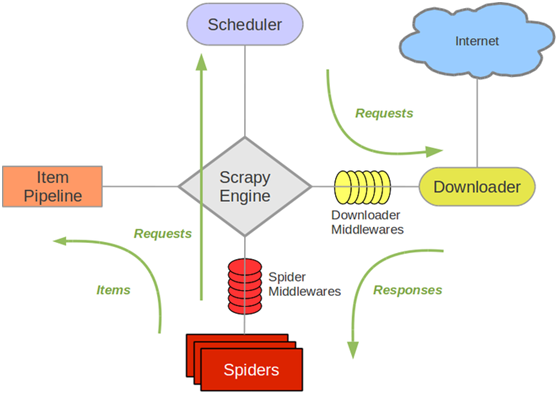
- Python scrapy爬取小說代碼案例詳解
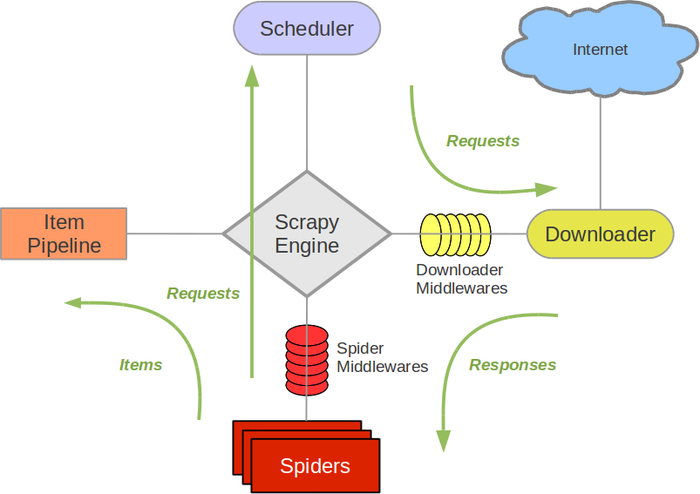
- scrapy是目前python使用的最廣泛的爬蟲框架架構圖如下解釋: Scrapy Engine(引擎): 負責Spider、ItemPipeline、Downloader、Scheduler中間的通訊,信號、數(shù)據(jù)傳遞等。 Scheduler(調(diào)度器): 它負責接受引擎發(fā)送過來的Request請...
- 日期:2022-07-18
- 瀏覽:44
-
- Python爬蟲框架-scrapy的使用
- Scrapy Scrapy是純python實現(xiàn)的一個為了爬取網(wǎng)站數(shù)據(jù)、提取結構性數(shù)據(jù)而編寫的應用框架。 Scrapy使用了Twisted異步網(wǎng)絡框架來處理網(wǎng)絡通訊,可以加快我們的下載速度,并且包含了各種中間件接口,可以靈活的完成各種需求1、安裝sudo pip3 install scra...
- 日期:2022-06-20
- 瀏覽:4
-
- 如何在django中運行scrapy框架
- 1.新建一個django項目,2.前端展示一個按鈕<form action='/start/' method='POST'> {% csrf_token %} <input type='submit' value='啟動爬蟲'></form>3.在dj...
- 日期:2024-10-09
- 瀏覽:5
- 標簽: Django

-
- Python Scrapy圖片爬取原理及代碼實例
- 1.在爬蟲文件中只需要解析提取出圖片地址,然后將地址提交給管道在管道文件對圖片進行下載和持久化存儲class ImgSpider(scrapy.Spider): name = ’img’ # allowed_domains = [’www.xxx.com’] start_urls = [’ht...
- 日期:2022-07-21
- 瀏覽:81
-
- Python爬蟲實例——scrapy框架爬取拉勾網(wǎng)招聘信息
- 本文實例為爬取拉勾網(wǎng)上的python相關的職位信息, 這些信息在職位詳情頁上, 如職位名, 薪資, 公司名等等.分析思路分析查詢結果頁在拉勾網(wǎng)搜索框中搜索’python’關鍵字, 在瀏覽器地址欄可以看到搜索結果頁的url為: ’https://www.lagou.com/jobs/list_pyth...
- 日期:2022-07-17
- 瀏覽:74
排行榜

 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備