Apache Doris Join 優(yōu)化原理詳解
目錄
- 背景 & 目標
- Doris 數(shù)據(jù)劃分
- Partition
- Bucket
- Join 方式
- 總覽
- Broadcast / Shuffle Join
- Bucket Shuffle Join
- Plan Rule
- Colocate Join
- Runtime Filter 優(yōu)化
- Join Reorder 優(yōu)化
- Join 調(diào)優(yōu)建議
背景 & 目標
- 掌握 Apache Doris Join 優(yōu)化手段及其實現(xiàn)原理
- 為代碼閱讀提供理論基礎(chǔ)
Doris 數(shù)據(jù)劃分
不同的 Join 方式非常依賴于對 Doris 中數(shù)據(jù)劃分方式的透徹理解。因此先在這里列舉出必要的基礎(chǔ)知識。
首先,在 Doris 中數(shù)據(jù)都以表(Table)的形式進行邏輯上的描述。
在 Doris 的存儲引擎中,用戶數(shù)據(jù)被水平劃分為若干個數(shù)據(jù)分片(Tablet,也稱作數(shù)據(jù)分桶 Bucket)。每個 Tablet 包含若干數(shù)據(jù)行。各個 Tablet 之間的數(shù)據(jù)沒有交集,并且在物理上是獨立存儲的。
一個 Tablet 只屬于一個數(shù)據(jù)分區(qū)(Partition)。而一個 Partition 包含若干個 Tablet。因為 Tablet 在物理上是獨立存儲的,所以可以視為 Partition 在物理上也是獨立的。Tablet 是數(shù)據(jù)移動、復制等操作的最小物理存儲單元。
若干個 Partition 組成一個 Table。Partition 可以視為是邏輯上最小的管理單元。數(shù)據(jù)的導入與刪除,僅能針對一個 Partition 進行。
Doris 支持兩層的數(shù)據(jù)劃分。第一層是 Partition,支持 Range 和 List 的劃分方式。第二層是 Bucket(Tablet),僅支持 Hash 的劃分方式。也可以僅使用一層分區(qū)。使用一層分區(qū)時,只支持 Bucket 劃分。
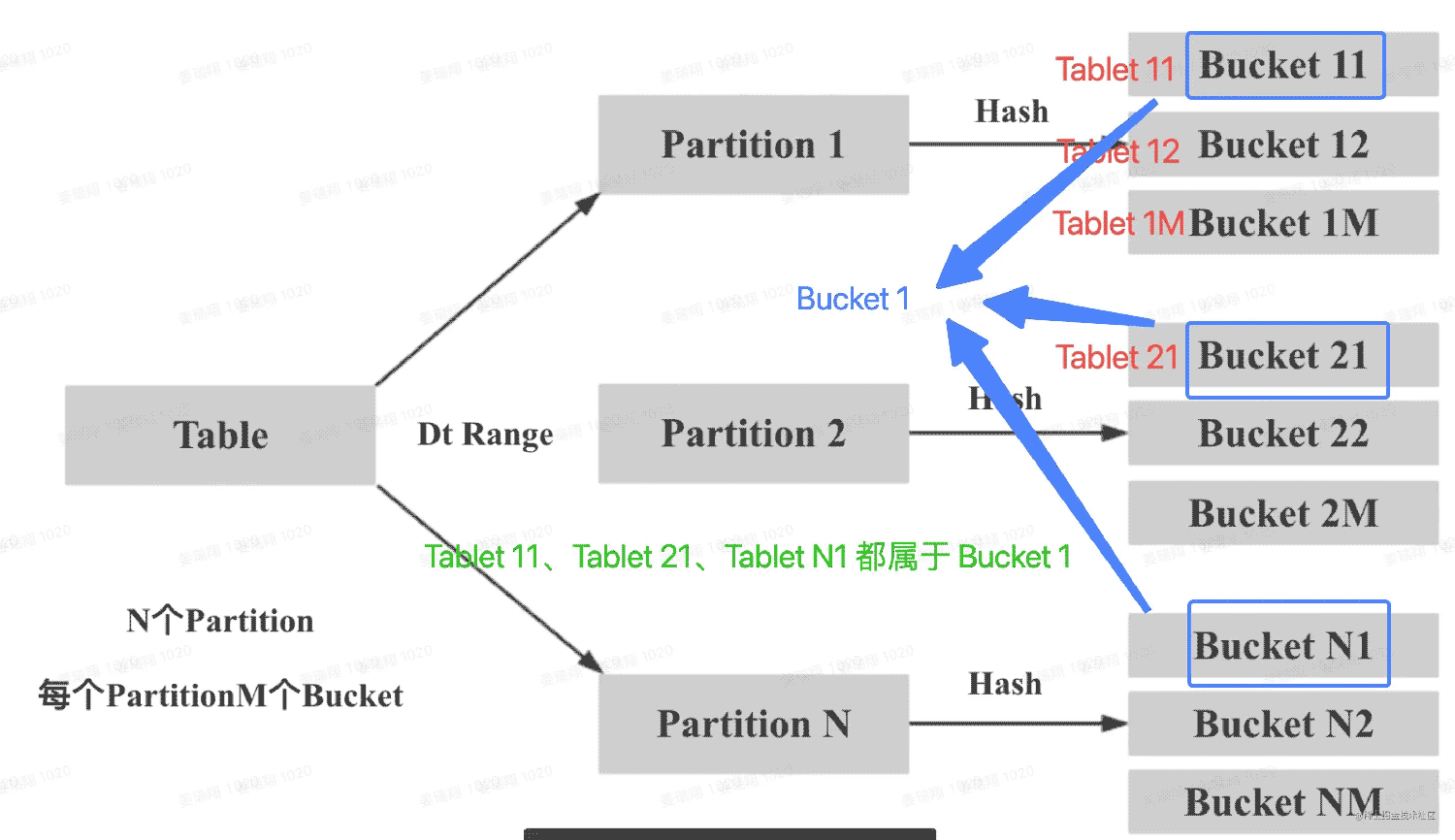
下圖說明 Table、Partition、Bucket(Tablet) 的關(guān)系:
- Table 按照 Range 的方式按照 date 字段進行分區(qū),得到了 N 個 Partition
- 每個 Partition 通過相同的 Hash 方式將其中的數(shù)據(jù)劃分為 M 個 Bucket(Tablet)
- 從邏輯上來說,Bucket 1 可以包含 N 個 Partition 中劃分得到的數(shù)據(jù),比如下圖中的 Tablet 11、Tablet 21、Tablet N1
特別注意:
Doris 中的 Partition 和 Bucket 定義可能和某些其它數(shù)據(jù)庫系統(tǒng)的定義有一些差異,下面配以一個具體的建表語句為例來說明:
CREATE TABLE IF NOT EXISTS example_db.expamle_range_tbl( `user_id` LARGEINT NOT NULL COMMENT "用戶id", `date` DATE NOT NULL COMMENT "數(shù)據(jù)灌入日期時間", `timestamp` DATETIME NOT NULL COMMENT "數(shù)據(jù)灌入的時間戳", `city` VARCHAR(20) COMMENT "用戶所在城市", `age` SMALLINT COMMENT "用戶年齡", `sex` TINYINT COMMENT "用戶性別", `last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01 00:00:00" COMMENT "用戶最后一次訪問時間", `cost` BIGINT SUM DEFAULT "0" COMMENT "用戶總消費", `max_dwell_time` INT MAX DEFAULT "0" COMMENT "用戶最大停留時間", `min_dwell_time` INT MIN DEFAULT "99999" COMMENT "用戶最小停留時間")ENGINE=OLAPAGGREGATE KEY(`user_id`, `date`, `timestamp`, `city`, `age`, `sex`)PARTITION BY RANGE(`date`)( PARTITION `p201701` VALUES LESS THAN ("2017-02-01"), PARTITION `p201702` VALUES LESS THAN ("2017-03-01"), PARTITION `p201703` VALUES LESS THAN ("2017-04-01"))DISTRIBUTED BY HASH(`user_id`) BUCKETS 16PROPERTIES( "replication_num" = "3");綠色高亮:Partition,此例中使用一個 date 字段進行分區(qū)
藍色高亮:Bucket,此例中使用 user_id 字段為作為分布列
Partition
- Partition 列可以指定一列或多列,分區(qū)列必須為 KEY 列
- 分區(qū)數(shù)量理論上沒有上限
- 當不使用 Partition 建表時,系統(tǒng)會自動生成一個和表名同名的,全值范圍的 Partition。該 Partition 對用戶不可見,并且不可刪改
創(chuàng)建分區(qū)時不可添加范圍重疊的分區(qū)
有兩種分區(qū)方式:
Bucket
- 如果使用了 Partition,則 DISTRIBUTED 語句描述的是數(shù)據(jù)在各個分區(qū)內(nèi)的劃分規(guī)則。如果不使用 Partition,則描述的是對整個表的數(shù)據(jù)劃分規(guī)則
- 分桶列的選擇,是在 查詢吞吐 和 查詢并發(fā) 之間的一種權(quán)衡:
- 如果選擇多個分桶列,則數(shù)據(jù)分布更均勻。如果一個查詢條件不包含所有分桶列的等值條件(意味著無法做桶裁剪以減少數(shù)據(jù)查詢范圍),那么該查詢會觸發(fā)所有分桶同時掃描,這樣查詢的吞吐會增加,單個查詢的延遲隨之降低。這個方式適合大吞吐低并發(fā)的查詢場景
- 如果僅選擇一個或少數(shù)分桶列,則對應的點查詢可以僅觸發(fā)一個分桶掃描(意味著可以做桶裁剪以減少數(shù)據(jù)查詢范圍)。此時,當多個點查詢并發(fā)時,這些查詢有較大的概率分別觸發(fā)不同的分桶掃描,各個查詢之間的 IO 影響較小,尤其當不同桶分布在不同磁盤上時),所以這種方式適合高并發(fā)的點查詢場景
- 分桶的數(shù)量理論上沒有上限
Join 方式
總覽
作為分布式的 MPP 數(shù)據(jù)庫, 在 Join 的過程中是需要進行數(shù)據(jù)的 Shuffle。數(shù)據(jù)需要進行拆分調(diào)度,才能保證最終的 Join 結(jié)果是正確的。舉個簡單的例子,假設(shè)關(guān)系 S 和 R 進行Join,N 表示參與 Join 計算的節(jié)點的數(shù)量;T 則表示關(guān)系的 Tuple 數(shù)目。
目前 Doris 支持的 Join 方式有以上 4 種,這 4 種方式靈活度和適用性是從高到低的,對數(shù)據(jù)分布的要求越來越嚴,但 Join 計算的性能則通過降低網(wǎng)絡(luò)開銷而越來越好。
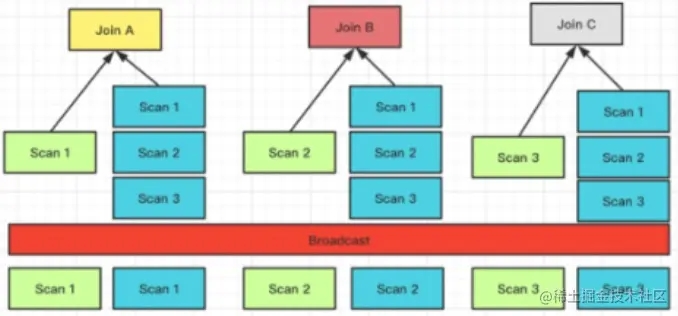
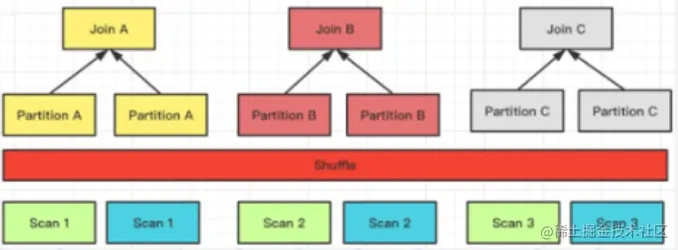
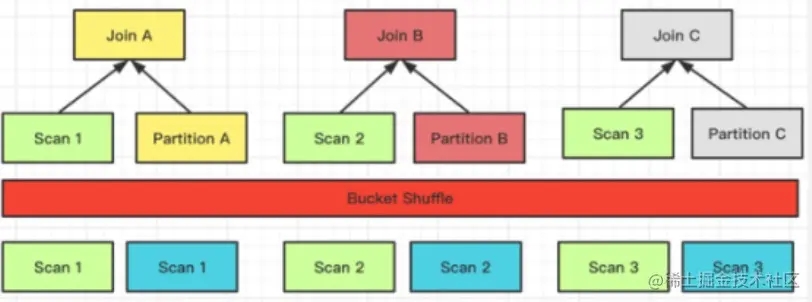
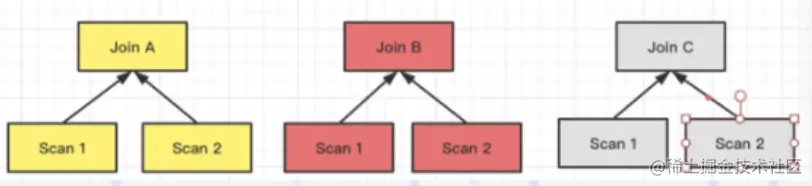
Join 方式的選擇是 FE 生成分布式計劃階段會考慮的事項之一。在 FE 進行分布式計劃時,優(yōu)先選擇的順序為(總是會優(yōu)先選擇預期性能最好的):Colocate Join -> Bucket Shuffle Join -> Broadcast Join -> Shuffle Join。
Colocate 以及 Bucket Shuffle 是可遇不可求的。當無法使用它們時,Doris會自動嘗試進行 Broadcast Join,如果預估小表過大則會自動切換至 Shuffle Join。
但是用戶可以通過顯式 Hint 來強制使用期望的 Join 類型,比如:
select * from test join [shuffle] baseall on test.k1 = baseall.k1;
Broadcast / Shuffle Join
原理比較簡單,這里不展開。
Bucket Shuffle Join
當 Join 條件命中了左表的數(shù)據(jù)分布列時,Broadcast 以及 Shuffle Join 會有非必要的網(wǎng)絡(luò)傳輸開銷。而 Bucket Shuffle Join 旨在解決這類問題,通過對左表實現(xiàn)本地性計算優(yōu)化,來減少左表數(shù)據(jù)在節(jié)點間的傳輸耗時,從而加速查詢。
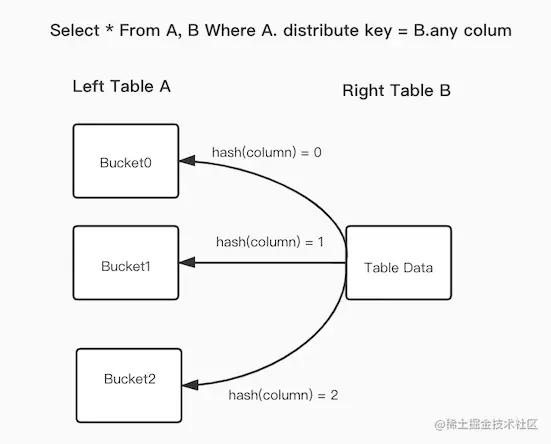
以上的例子中,Join 的等值表達式命中了表 A(左表)的數(shù)據(jù)分布列。Bucket Shuffle Join 會根據(jù)表 A 的數(shù)據(jù)分布信息,將表 B(右表)的數(shù)據(jù)發(fā)送到對應表 A 的數(shù)據(jù)計算節(jié)點。
定性分析上:
- 降低了網(wǎng)絡(luò)與內(nèi)存開銷(相比 Broadcast 以及 Shuffle Join 都不會更差),使一類 Join 查詢有更好的性能。尤其是當 FE 能夠執(zhí)行左表的分區(qū)裁剪與桶裁剪時
- 與 Colocate Join 不同,它對于表的數(shù)據(jù)分布方式?jīng)]有侵入性,對于用戶來說是透明的。對于表的數(shù)據(jù)分布沒有強制性的要求(體現(xiàn)在建表語句中不需要顯式地設(shè)置 colocate_with 屬性),不容易導致數(shù)據(jù)傾斜的問題
- 可以為 Join Reorder 提供更多可能的優(yōu)化空間
Plan Rule
- Bucket Shuffle Join 只生效于 Join 條件為等值的場景,原因與 Colocate Join 類似,它們都依賴 Hash 來計算確定的數(shù)據(jù)分布
- 在等值 Join 條件之中包含兩張表的分桶列,當左表的分桶列為等值的 Join 條件時,它有很大概率會被規(guī)劃為 Bucket Shuffle Join
- 由于不同的數(shù)據(jù)類型的 Hash 值計算結(jié)果不同,所以 Bucket Shuffle Join 要求左表的分桶列的類型與右表等值 Join 列的類型需要保持一致,否則無法進行對應的規(guī)劃
- Bucket Shuffle Join 只作用于 Doris 原生的 OLAP 表,對于 ODBC,MySQL,ES 等外表,當其作為左表時是無法規(guī)劃生效的
- 對于分區(qū)表,由于每一個分區(qū)的數(shù)據(jù)分布規(guī)則可能不同,所以 Bucket Shuffle Join 只能保證左表為單分區(qū)時生效。所以在 SQL 執(zhí)行之中,需要盡量使用 where 條件使分區(qū)裁剪的策略能夠生效
- 假如左表為 Colocate 的表,那么它每個分區(qū)的數(shù)據(jù)分布規(guī)則是確定的,Bucket Shuffle Join 能在Colocate 表上表現(xiàn)更好
Colocate Join
可以理解為在數(shù)據(jù)分布滿足一定條件的前提下,減少一切不必要的網(wǎng)絡(luò)傳輸開銷,實現(xiàn)完全的計算本地化來加速查詢。同時因為沒有網(wǎng)絡(luò)傳輸開銷,BE 節(jié)點可以擁有更高的并發(fā)度,從而進一步提升 Join 性能。
要理解這個算法,需要先了解兩個術(shù)語:
- Colocation Group(CG):一個 CG 中會包含一張及以上的 Table。在同一個 Group 內(nèi)的 Table 有著相同的 Colocation Group Schema,并且有著相同的數(shù)據(jù)分片分布
- Colocation Group Schema(CGS):用于描述一個 CG 中的 Table,和 Colocation 相關(guān)的通用 Schema 信息。包括分桶列類型,分桶數(shù)以及副本數(shù)等
和 Buckets Sequence 這一概念:
一個表的數(shù)據(jù),最終會根據(jù)分桶列值 Hash、對桶數(shù)取模后落在某一個分桶內(nèi)。假設(shè)一個 Table 的分桶數(shù)為 8,則共有 [0, 1, 2, 3, 4, 5, 6, 7] 8 個分桶(Bucket),我們稱這樣一個序列為一個 BucketsSequence。每個 Bucket 內(nèi)會有一個或多個數(shù)據(jù)分片(Tablet)。當表為單分區(qū)表時,一個 Bucket 內(nèi)僅有一個 Tablet。如果是多分區(qū)表,則會有多個(因為多個 Partition 中的不同 Tablet 會被劃分到相同的 Bucket)。
Colocation Join 功能,是將一組擁有相同 CGS 的 Table 組成一個 CG。并保證這些 Table 對應的數(shù)據(jù)分片會落在同一個 BE 節(jié)點上。使得當 CG 內(nèi)的表進行分桶列上的 Join 操作時,可以通過直接進行本地數(shù)據(jù) Join,減少數(shù)據(jù)在節(jié)點間的傳輸耗時。
因此關(guān)鍵問題就轉(zhuǎn)變?yōu)榱恕溉绾伪WC這些 Table 對應的數(shù)據(jù)分片會落在同一個 BE 節(jié)點上?」
通過同一 CG 內(nèi)的 Table 必須保證以下屬性相同實現(xiàn):
- 分桶列和分桶數(shù)
分桶列,即在建表語句中 DISTRIBUTED BY HASH(col1, col2, ...) 中指定的列。分桶列決定了一張表的數(shù)據(jù)通過哪些列的值進行 Hash 劃分到不同的 Tablet 中。同一 CG 內(nèi)的 Table 必須保證分桶列的類型和數(shù)量完全一致,并且桶數(shù)一致,才能保證多張表的數(shù)據(jù)分片能夠一一對應的進行分布控制。
- 副本數(shù)
同一個 CG 內(nèi)所有表的所有分區(qū)(Partition)的副本數(shù)必須一致。如果不一致,可能出現(xiàn)某一個 Tablet 的某一個副本,在同一個 BE 上沒有其他的表分片的副本對應。不過,同一個 CG 內(nèi)的表,分區(qū)的個數(shù)、范圍以及分區(qū)列的類型不要求一致。
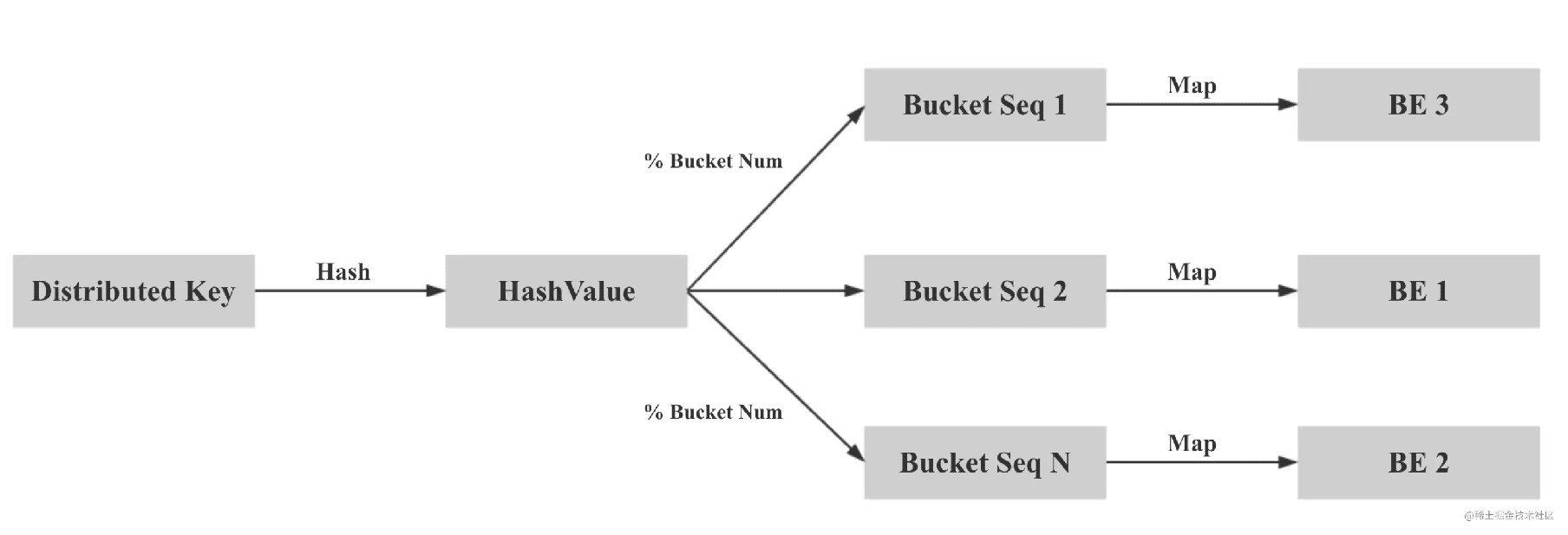
在固定了分桶列和分桶數(shù)后,同一個 CG 內(nèi)的表會擁有相同的 BucketsSequence。而副本數(shù)決定了每個分桶內(nèi)的 Tablet 的多個副本,存放在哪些 BE 上。假設(shè) BucketsSequence 為 [0, 1, 2, 3, 4, 5, 6, 7],BE 節(jié)點有 [A, B, C, D] 4個。則一個可能的數(shù)據(jù)分布如下:
+---+ +---+ +---+ +---+ +---+ +---+ +---+ +---+| 0 | | 1 | | 2 | | 3 | | 4 | | 5 | | 6 | | 7 |+---+ +---+ +---+ +---+ +---+ +---+ +---+ +---+| A | | B | | C | | D | | A | | B | | C | | D || | | | | | | | | | | | | | | || B | | C | | D | | A | | B | | C | | D | | A || | | | | | | | | | | | | | | || C | | D | | A | | B | | C | | D | | A | | B |+---+ +---+ +---+ +---+ +---+ +---+ +---+ +---+
CG 內(nèi)所有表的數(shù)據(jù)都會按照上面的規(guī)則進行統(tǒng)一分布,這樣就保證了,分桶列值相同的數(shù)據(jù)都在同一個 BE 節(jié)點上,可以進行本地數(shù)據(jù) Join。其核心思想是「兩次映射」,保證相同的 Distributed Key 的數(shù)據(jù)會被映射到相同的 Bucket Sequence,再保證 Bucket Sequence 對應的 Bucket 映射到相同的 BE 節(jié)點:
通過查詢計劃可以檢查一個查詢是否使用了 Colocate Join,同時計劃中的 Exchange Node 也被去掉了,會將 ScanNode 直接設(shè)置為 Hash Join Node 的孩子節(jié)點。
DESC SELECT * FROM tbl1 INNER JOIN tbl2 ON (tbl1.k2 = tbl2.k2);-- 在 Hash Join 節(jié)點會顯示:-- colocate: true/false
Colocate Join 十分適合幾張表按照相同字段分桶,并高頻根據(jù)固定的字段 Join 的場景。這樣可以將數(shù)據(jù)預先存儲到相同的分桶中,實現(xiàn)本地計算。
Runtime Filter 優(yōu)化
Doris 在進行 Hash Join 計算時會在右表構(gòu)建一個 Hash Table,左表流式地通過右表的 Hash Table 從而得出 Join 結(jié)果。而 Runtime Filter 就是充分利用了右表的 Hash Table 構(gòu)建階段去做一些額外的事情。
在右表生成 Hash Table 的時,同時生成一個基于 Hash Table 數(shù)據(jù)的一個過濾條件,然后下推到左表的數(shù)據(jù)掃描節(jié)點。通過這樣的方式,Doris 可以在運行時進行數(shù)據(jù)過濾。
假如左表是一張大表,右表是一張小表,那么利用下推到左表的過濾條件就可以把絕大多數(shù) Join 層要過濾的數(shù)據(jù)在數(shù)據(jù)讀取時就提前過濾(如果能夠下推到引擎層,還能夠利用 Doris 針對 Key 列過濾的延遲物化),從而大幅度地提升 Join 查詢的性能。
Runtime Filter 在查詢規(guī)劃時生成,在 HashJoinNode 中構(gòu)建,在 ScanNode 中應用。比如 T1(行數(shù) 10w) 和 T2(行數(shù) 2k) 的 Join 操作:
| > HashJoinNode <| | || | 100000 | 2000| | || OlapScanNode OlapScanNode| ^ ^ | | 100000 | 2000|T1T2|
顯而易見對 T2 掃描數(shù)據(jù)要遠遠快于 T1,如果我們主動等待一段時間再掃描 T1,等 T2 將掃描的數(shù)據(jù)記錄交給 HashJoinNode 后,HashJoinNode 根據(jù) T2 的數(shù)據(jù)計算出一個過濾條件,比如 T2 數(shù)據(jù)的最大和最小值,或者構(gòu)建一個 Bloom Filter,接著將這個過濾條件發(fā)給等待掃描 T1 的 ScanNode,后者應用這個過濾條件,將過濾后的數(shù)據(jù)交給 HashJoinNode,從而減少 probe hash table 的次數(shù)和網(wǎng)絡(luò)開銷,這個過濾條件就是 Runtime Filter,效果如下:
| > HashJoinNode <| | || | 6000 | 2000| | || OlapScanNode OlapScanNode| ^ ^ | | 100000 | 2000|T1T2|
如果能將過濾條件(Runtime Filter)下推到存儲引擎,則某些情況可以利用索引(比如 Join 列為 Key 列,可以利用延遲物化能力)來直接減少掃描的數(shù)據(jù)量,從而大大減少掃描耗時,效果如下:
| > HashJoinNode <| | || | 6000 | 2000| | || OlapScanNode OlapScanNode| ^ ^ | | 6000 | 2000|T1T2|
可見,和謂詞下推、分區(qū)裁剪不同,Runtime Filter 是在運行時動態(tài)生成的過濾條件,即在查詢運行時解析 Join 條件確定過濾表達式,并將表達式下推給正在讀取左表的 ScanNode,從而減少掃描的數(shù)據(jù)量,進而減少 probe hash table 的次數(shù),避免不必要的 IO 和網(wǎng)絡(luò)傳輸。因為其運行時生效的特性,官方認為它是 Adaptive Query Execution 的一種應用。
根據(jù)上面的例子,可以推導出場景滿足以下的條件時,使用 Runtime Filter 的效果會比較好:
- 左表大右表小(當右表上還有額外的過濾條件會更理想),因為構(gòu)建 Runtime Filter 是需要承擔計算成本的,包括一些內(nèi)存的開銷,而開銷直接取決于右表的實際數(shù)據(jù)量
- 左右表 Join 出來的結(jié)果很少,說明通過 Runtime Filter 可以過濾掉左表的絕大部分數(shù)據(jù)
Doris 支持 3 種 Runtime Filter:
- 一種是 IN,很好理解,將一個 hashset 下推到數(shù)據(jù)掃描節(jié)點。
- 第二種就是 BloomFilter,就是利用哈希表的數(shù)據(jù)構(gòu)造一個 BloomFilter,然后把這個 BloomFilter 下推到查詢數(shù)據(jù)的掃描節(jié)點。
- 最后一種就是 MinMax,就是個 Range 范圍,通過右表數(shù)據(jù)確定 Range 范圍之后,下推給數(shù)據(jù)掃描節(jié)點。
工作原理和優(yōu)劣總結(jié)如下:
一些使用的注意事項(比較細節(jié)了,后面考慮結(jié)合代碼再深入理解):
開啟 Runtime Filter 后,左表的 ScanNode 會為每一個分配給自己的 Runtime Filter 等待一段時間再掃描數(shù)據(jù),即如果 ScanNode 被分配了 3 個 Runtime Filter,那么它最多會等待 3000ms。
因為 Runtime Filter 的構(gòu)建和合并均需要時間,ScanNode 會嘗試將等待時間內(nèi)到達的 Runtime Filter 下推到存儲引擎,如果超過等待時間后,ScanNode 會使用已經(jīng)到達的 Runtime Filter 直接開始掃描數(shù)據(jù)。
如果 Runtime Filter 在 ScanNode 開始掃描之后到達,則 ScanNode 不會將該 Runtime Filter 下推到存儲引擎,而是對已經(jīng)從存儲引擎掃描上來的數(shù)據(jù),在 ScanNode 上基于該 Runtime Filter 使用表達式過濾,之前已經(jīng)掃描的數(shù)據(jù)則不會應用該 Runtime Filter,這樣得到的中間數(shù)據(jù)規(guī)模會大于最優(yōu)解,但可以避免嚴重的劣化。
如果集群比較繁忙,并且集群上有許多資源密集型或長耗時的查詢,可以考慮增加等待時間,以避免復雜查詢錯過優(yōu)化機會。如果集群負載較輕,并且集群上有許多只需要幾秒的小查詢,可以考慮減少等待時間,以避免每個查詢增加 1s 的延遲。
Join Reorder 優(yōu)化
有了前面兩表 Join 的 Runtime Filter 鋪墊,再來看 Join Reorder 的優(yōu)化,邏輯關(guān)系上就能夠理順了。
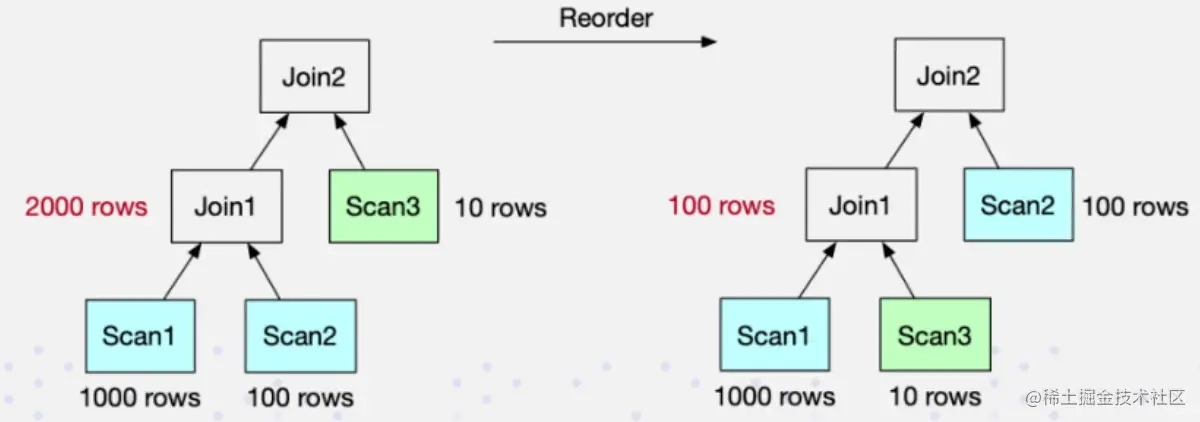
Doris 目前的 Join Reorder 算法是基于 RBO 的,邏輯描述如下:
- 盡量讓大表跟小表做 Join,它生成的中間結(jié)果是盡可能小的
- 把有條件的 Join 表往前放,也就是說盡量讓有條件的 Join 表進行過濾
- Hash Join 的優(yōu)先級高于 Nest Loop Join,因為 Hash join 本身是比 Nest Loop Join 快很多的
可以發(fā)現(xiàn)前兩條,都是在朝著讓「右表」更小的方向去優(yōu)化,而最后一條則是從算法的性能上來考慮。
Join 調(diào)優(yōu)建議
- Join 列最好是相同的簡單類型;同類型避免 Cast 操作,簡單類型則有不錯的 Join 計算性能
- Join 列最好是 Key 列,原因是 Key 列能夠充分利用 Doris 延遲物化的特性,減少 IO 提升性能
- 大表之間的 Join 最好能夠利用上 Colocate,相當于已經(jīng)做好了預 Shuffle,實際查詢的時候可以直接 Join 計算不再有 Shuffle 操作,徹底避免了大表的 Shuffle 網(wǎng)絡(luò)開銷
- 利用 Runtime Filter,Join 過濾性高時效果顯著。根據(jù) 3 種 Runtime Filter 特點選擇最適合的
- 涉及多表 Join,需要判斷 Join 的合理性。盡量保證“左大右小”的原則,HashJoin 優(yōu)于 NLJ。必要時可以通過 SQL Rewrite,通過 Hint 來調(diào)整 Join 順序
REF
以上就是Apache Doris Join 優(yōu)化原理詳解的詳細內(nèi)容,更多關(guān)于Apache Doris Join 優(yōu)化的資料請關(guān)注其它相關(guān)文章!
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備