Apache Pulsar 微信大流量實時推薦場景下實踐詳解
目錄
- 導語
- 作者簡介
- 實踐 1:大流量場景下的 K8s 部署實踐
- 實踐 2:非持久化 Topic 的應用
- 實踐 3:負載均衡與 Broker 緩存優化
- 實踐 4:COS Offloader 開發與應用
- 未來展望與計劃
導語
本文整理自 8 月 Apache Pulsar Meetup 上,劉燊題為《Apache Pulsar 在微信的大流量實時推薦場景實踐》的分享。本文介紹了微信團隊在大流量場景下將 Pulsar 部署在 K8s 上的實踐與優化、非持久化 Topic 的應用、負載均衡與 Broker 緩存優化實踐與COS Offloader 開發與應用。
作者簡介
劉燊,騰訊微信高級研發工程師,Apache Pulsar Contributor。
在通信社交領域,微信已經成為國內當之無愧的社交霸主。用戶人數在 2018 年突破了 10 億,截至 2021 年第三季度末,微信每月活動賬戶總數已達到 12.6 億人,可以說,微信已經成為國人生活的一部分。
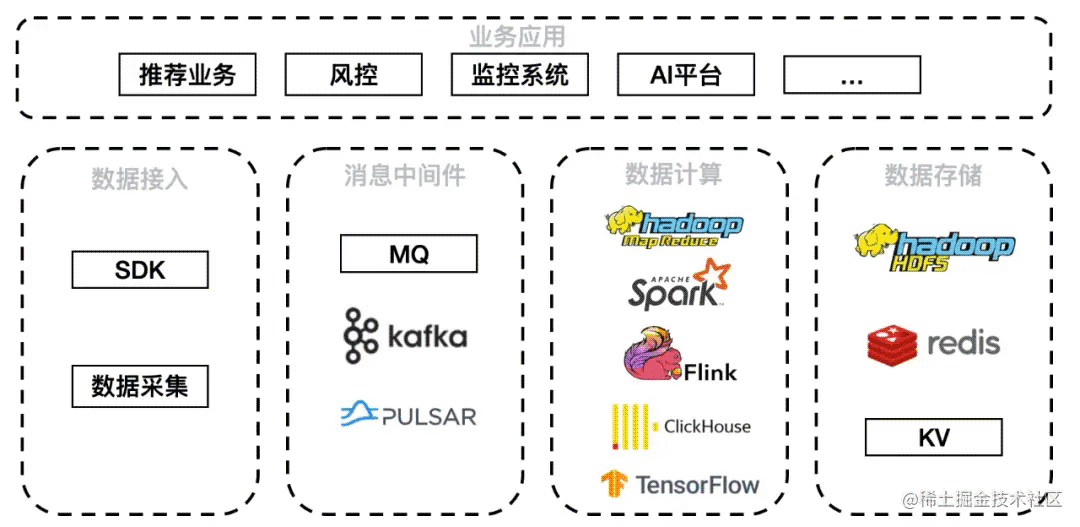
微信的業務場景包括推薦業務、風控、監控系統、AI 平臺等。數據通過 SDK 和數據采集方式接入,經由 MQ、Kafka、Pulsar 消息中間件,其中 Pulsar 發揮了很大的作用。中間件下游接入數據計算層 Hadoop、Spark、Flink、ClickHouse、TensorFlow 等計算平臺,由于本次介紹實時推薦場景,因此較多使用 Flink 和 TensorFlow。落地存儲平臺則包括 HDFS、HBase、Redis 以及各類自研 KV。
團隊選型 Pulsar 的初期目標是獲得一個滿足大數據流量場景并且運維管理便捷的消息隊列系統。最終選擇 Pulsar 的主要原因有五點:
- 在騰訊自研上云的大背景下,團隊非常看重云原生特性。Pulsar 的云原生特性,包括分布式、彈性伸縮、讀寫分離等都體現出優勢。Pulsar 邏輯層 Broker 無狀態,直接提供服務。存儲層 Bookie 有狀態,但是節點對等,且 Bookie 自帶多副本容災;
- Pulsar 支持資源隔離,可以軟隔離或硬隔離,避免不同業務之間互相影響;
- Pulsar 支持靈活的 Namespace/Topic 策略管控,對集群的管理和維護有很大幫助;
- Pulsar 能夠便捷擴容,邏輯層 Broker 的無狀態和負載均衡策略允許快速擴容,存儲層 Bookie 節點之間互相對等也便于快速擴容,可以輕松應對流量暴漲場景;
- Pulsar 具備多語言客戶端能力,微信的業務場景中涉及 C/C++、TensorFlow、Python 等語言,Pulsar 可以滿足需求。
實踐 1:大流量場景下的 K8s 部署實踐
微信團隊使用了 Pulsar 官網提供的 K8s Helm chart 部署方式。
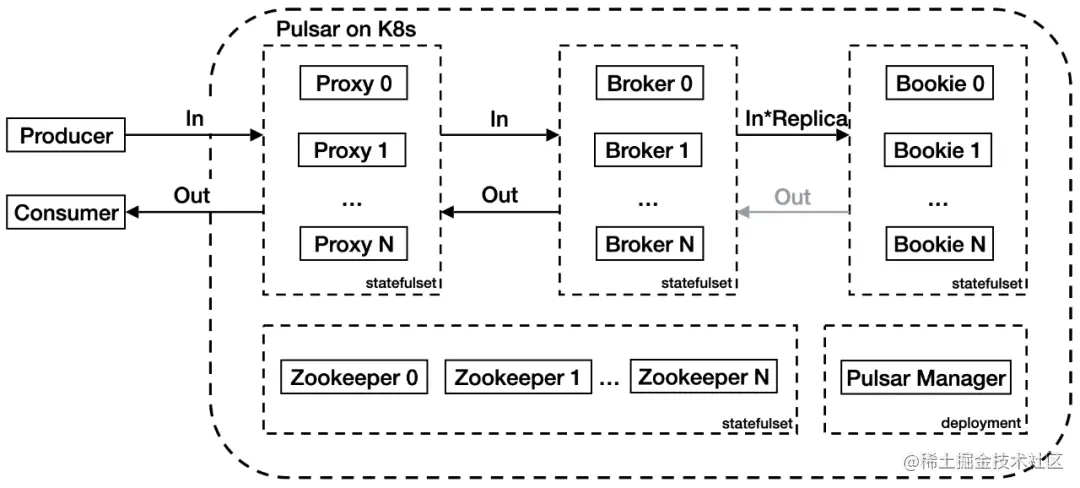
原生部署架構中,流量從 Proxy 代理層進入,經過 Broker 邏輯服務層寫入 Bookie 存儲層。Proxy 代理層代理客戶端和 Broker 之間的連接,Broker 層管理 Topic,Bookie 層負責持久化消息存儲。在上圖中,入流量和出流量分別用 In 和 Out 進行標記,Replica 是配置的副本。
在應用的過程中團隊發現了兩個問題:首先 Proxy 代理了 Pulsar 客戶端的請求,導致 Broker 無法獲取客戶端 IP,增加了運維難度;其次,當集群流量較大時,集群內部帶寬會成為瓶頸。上圖架構內,集群入流量為 (2+ 副本數)倍;出流量最大為 3 倍,Consumer、Proxy、Broker 和 Bookie 間分別有一倍流量,但是僅極端情況下流量會全量從 Bookie 流出。假設出入流量都是 10 GBps,副本數為 3,集群內入流量會放大為 50 GBps,出流量會放大為 30 GBps。另外默認情況下 Proxy 服務只有一個負載均衡器承載所有流量,壓力巨大。
這里可以看出瓶頸主要出現在 Proxy 層,該層造成了很大流量浪費。而 Pulsar 實際上支持 Broker 直連,因此團隊在此基礎上進行了一些優化:
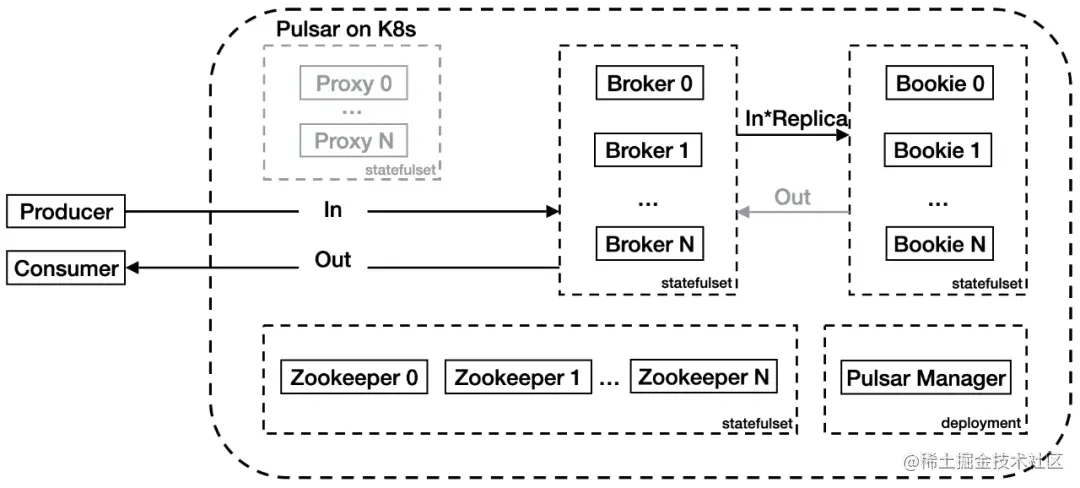
團隊利用了騰訊云 K8s 集群的能力,給 Broker 配置了彈性網卡,并使 Broker 的 IP 直接暴露在集群外,可以被外部客戶端直接訪問。Broker 服務也配置了負載均衡器。這樣客戶端可以直接訪問負載均衡器 IP,再經過 Pulsar 內部協議的 Lookup 操作找到要訪問的 Topic 所處的 Broker。由此節省了 Proxy 帶來的額外帶寬消耗。
團隊在 K8s 部署方面還做了以下優化工作:
- 如上文所述去 Proxy;
- Bookie 使用多盤多目錄 + 本地 SSD 提升性能,由于原社區版本 Pulsar 不支持多盤多目錄,這里團隊做了改進支持并合并入社區(github.com/apache/puls…);
- 日志采集使用騰訊云 CLS(日志服務),統一的日志服務可以簡化分布式多節點系統的運維、問題查詢操作;
- 指標采集使用 Grafana + Kvass + Thanos,默認指標采集使用了單機服務,很快出現了性能瓶頸,優化后問題解決且支持水平擴容。
實踐 2:非持久化 Topic 的應用
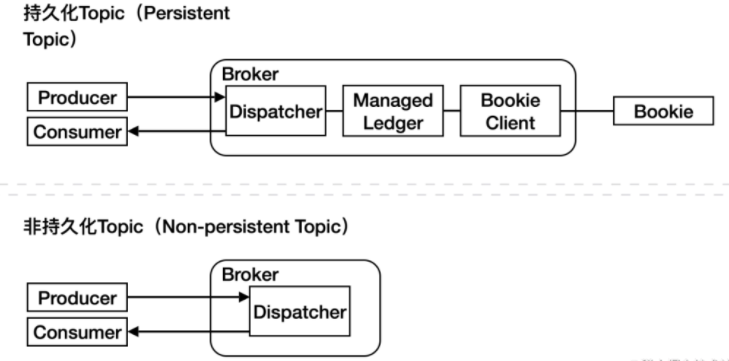
生產者和消費者是同 Broker 中的 Dispatcher 模塊交互的,而持久化 Topic 中生產者數據會通過 Dispatcher 進入 Managed Ledger 模塊,再調用 Bookie 客戶端與 Bookie 交互。非持久化 Topic 中數據不會進入 Managed Ledger,而是直接發送給消費者。在大流量場景中,非持久化 Topic 由于不需要與 Bookie 交互,對集群的帶寬壓力會明顯降低。
非持久化 Topic 在大流量實時推薦場景中有應用,但具體的應用場景必須滿足“可容忍少量數據丟失”的要求。實踐中有三種場景滿足這一要求:
- 大流量 + 消費端處理能力不足的實時訓練任務;
- 時效性敏感的實時訓練任務;
- 抽樣評測任務。
實踐 3:負載均衡與 Broker 緩存優化
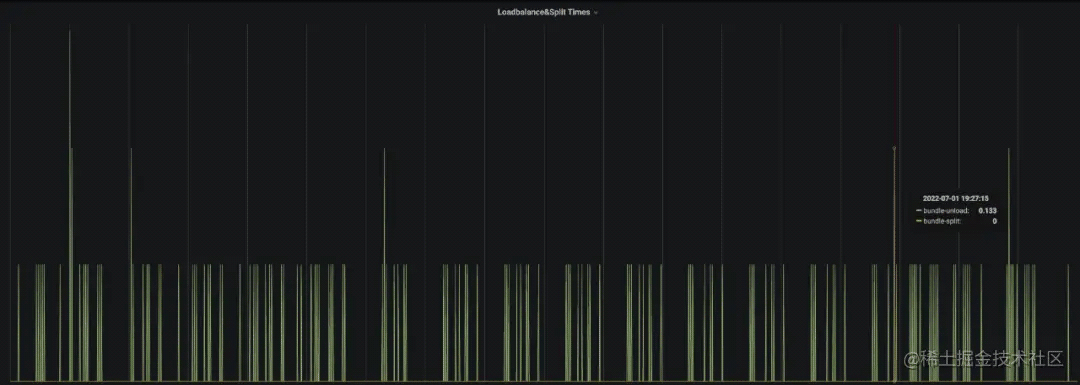
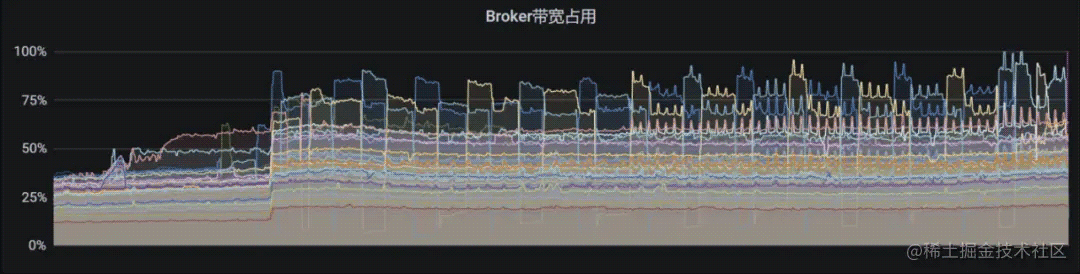
以上是一個線上真實的場景。生產環境中出現了反復 bundle unload 的問題,導致 Broker 負載反復波動。
該場景中使用了以下負載均衡配置:
loadManagerClassName=org.apache.pulsar.broker.loadbalance.impl.ModularLoadManagerImplloadBalancerLoadSheddingStrategy=org.apache.pulsar.broker.loadbalance.impl.ThresholdShedderloadBalancerBrokerThresholdShedderPercentage=10loadBalancerBrokerOverloadedThresholdPercentage=70Load bundle處理類(select for broker):org.apache.pulsar.broker.loadbalance.impl.LeastLongTermMessageRate
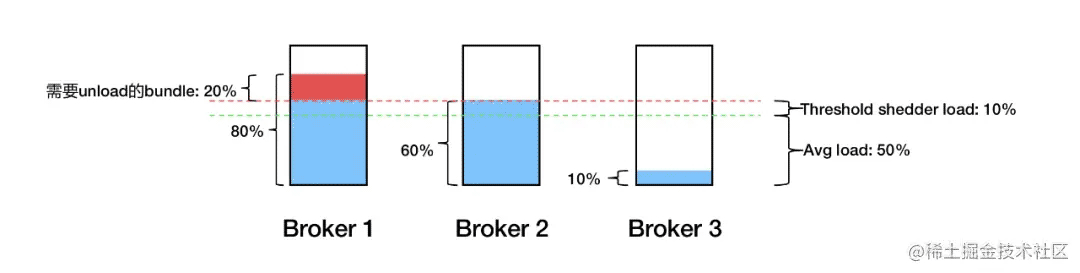
如上圖,假設三個 Broker 平均負載是 50%,則閾值就是 60%,超出 60% 的部分需要均衡。但實際應用中發現 Broker 1 的多余 20% 負載會卸載到 Broker 2 上,之后由于 Broker 2 超載所以又會卸載下來,還會回到 Broker 1 上。結果流量就在 Broker 1 和 Broker 2 上反復橫跳。
跟蹤代碼發現,Load Bundle 處理類是根據 Broker 的消息量判斷該承載多余流量的 Broker,但生產中消息量與機器負載并不完全正相關,且 Threshold shedder 是根據 CPU、出入流量、內存等多種指標平均加權得出 Broker 負載,所以 bundle 的加載和卸載邏輯并不一致。
對此團隊進行了代碼優化改進:
loadManagerClassName=org.apache.pulsar.broker.loadbalance.impl.ModularLoadManagerImplloadBalancerLoadSheddingStrategy=org.apache.pulsar.broker.loadbalance.impl.ThresholdShedderloadBalancerBrokerThresholdShedderPercentage=10loadBalancerBrokerOverloadedThresholdPercentage=70Load bundle處理類(select for broker):在低于平均負載的broker中隨機選擇loadBalancerDistributeBundlesEvenlyEnabled=false (相同的代碼實現:PR-16059)
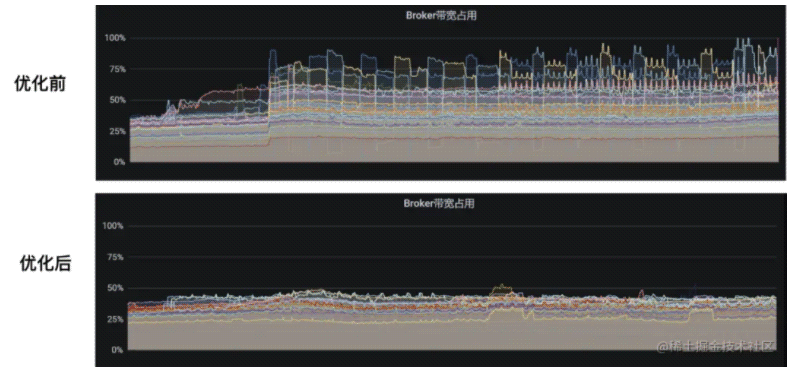
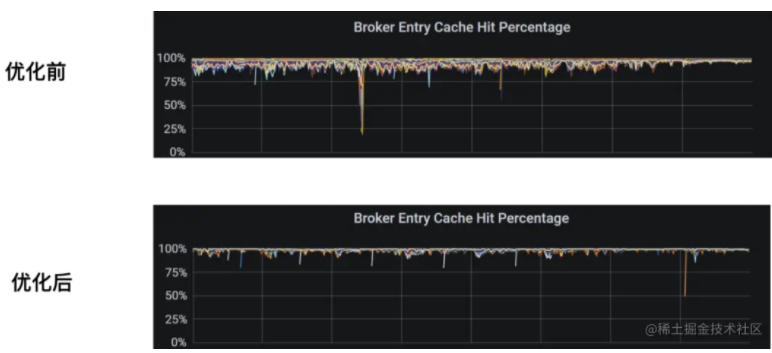
優化后的效果如下,可以看到集群流量穩定許多:
團隊還在實時推薦場景下優化了 Broker 緩存。這種場景有以下特征:
- 消費任務數量眾多;
- 消費速度參差不齊;
- 消費任務經常重啟。
對此,社區原有的 Broker 緩存邏輯效果不佳。以下是 Broker 緩存的原有驅逐邏輯:
void doCacheEviction(long maxTimestamp) { if (entryCache.getsize() <= 0) {return; } // Always remove all entries already read by active cursors PositionImpl slowestReaderPos = getEarlierReadPositionForActiveCursors); if (slowestReaderPos != null) {entryCache.invalidateEntries(slowestReaderPos): } // Remove entries older than the cutoff threshold entryCache.invalidateEntriesBeforeTimestamp(maxTimestamp);}默認策略會找出當前消費不活躍(由閾值控制,Cursor 消費的 entry 超過閾值即被認為是不活躍)的 Cursor,對 Cursor 之前的數據做驅逐。對此,騰訊工程師向社區提交了代碼改進:
void doCacheEviction (long maxTimestamp){ if (entryCache.getSize() (= 0) {return; ) PositionImpl evictionPos; if (config.isCacheEvictionByMarkDeletedPosition()){evictionPos=getEarlierMarkDeletedPositionForActiveCursors().getNext(); } else {// Always remove all entries already read by active cursorsevictionPos=getEarlierReadPositionForActiveCursors(); } if (evictionPos != null) {entryCache.invalidateEntries(evictionPos); } // Remove entries older than the cutoff threshold entryCache.invalidateEntriesBeforeTimestamp(maxTimestamp);}這里將選擇非活躍 Cursor 的邏輯改成了尋找需要刪除的數據位置。這樣消費速度相對較慢的數據就不會穿越到 Bookie 中增加集群壓力,只要數據有 Backlog 就會被緩存。但這種方法會導致緩存空間吃緊,因為消費任務重啟期間仍舊要無意義地保留緩存,占用緩存空間。
對此微信團隊在社區改進的基礎上又做了調整:
void doCacheEviction(long maxTimestamp){ if (entryCache.getSize() <= 0) {return; } if (factory.getConfig().isRemoveReadEntriesInCache()){PositionImpl evictionPos;if (config.isCacheEvictionByMarkDeletedPosition()){ PositionImplearlierMarkDeletedPosition=getEarlierMarkDeletedPositionForActiveCursors(); evictionPos = earlierMarkDeletedPosition != null? earlierMarkDeletedPosition.getNext() : null;} else { // Always remove all entries already read by active cursors evictionPos=getEarlierReadPositionForActiveCursors();}if (evictionPos != null) { entryCache.invalidateEntries(evictionPos);} } //Remove entries older than the cutoff threshold entryCache.invalidateEntriesBeforeTimestamp(maxTimestamp);}這里簡單地將一定時間內的數據緩存到 Broker 中,有效提升了場景中的緩存效率:
實踐 4:COS Offloader 開發與應用
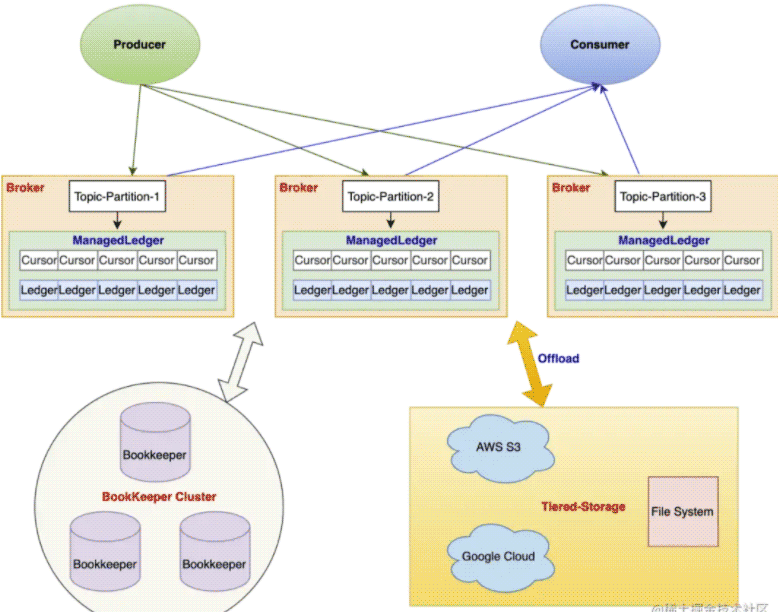
Pulsar 提供了分層存儲能力,可以將存儲轉移到廉價的存儲層。Pulsar Offloader 可以將超過一定時長的 Ledger 搬運到遠端存儲,不再停留在 Bookie 層,由 Broker 接管這部分的數據管理。
團隊使用 Pulsar Offloader 的原因有:
- Bookie Journal/Ledger 盤都使用 SSD,成本較高;
- 業務需求存儲時間長、數據存儲量大;
- 數據消費任務異常,需要容忍較長時間的數據 Backlog;
- 數據回放需求。
Pulsar 社區版本并不支持騰訊云對象存儲(COS),所以團隊開發了內部云上 COS Offloader 插件并應用于線上。
未來展望與計劃
團隊在部署與使用過程中一直和社區密切溝通,團隊未來計劃跟進社區版本升級與 bug 修復。微信團隊將著重參與一些特性,比如 PIP 192 Broker 負載均衡與緩存優化,計劃重構負載均衡器;PIP 180 通過影子 Topic 解決讀放大問題,幫助精細化管理 Topic。微信團隊也在關注 Pulsar 生態進展,如 Flink、Pulsar、數據湖全鏈路打通。
以上就是Apache Pulsar 微信大流量實時推薦場景下實踐詳解的詳細內容,更多關于Apache Pulsar微信大流量推薦的資料請關注其它相關文章!
 網公網安備
網公網安備