MySQL之索引結構解讀
目錄
- MySQL索引是什么
- 二叉樹
- 紅黑樹
- B+Tree
- 總結
MySQL索引是什么
MySQL索引就是幫助MySQL高效獲取數據的數據結構。
這個數據結構也就是我們常說的二叉樹、紅黑樹、Hash表等索引數據結構,借助這樣的數據結構,相較于之前的全局遍歷查詢,能夠更高效的進行查詢。
簡單復習一下一些常見的索引數據結構:
二叉樹
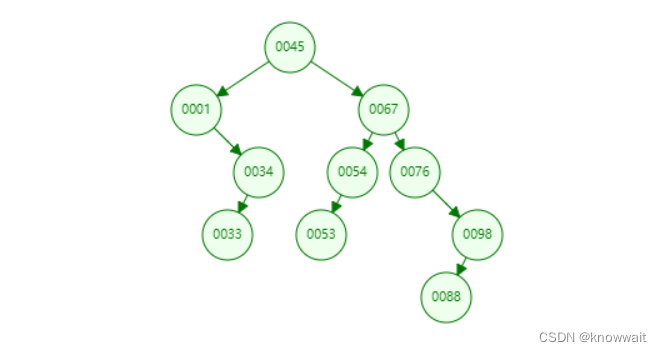
上圖是一個二叉樹,他根據我們存放數據的順序依次填充這個樹結構,比根節點小的數放到左邊,比根節點大的放在右邊,這樣我們去查找的時候不需要遍歷所有數據,只需要依次與根節點以及下面的子節點對比就可以查找到我們要找的元素。
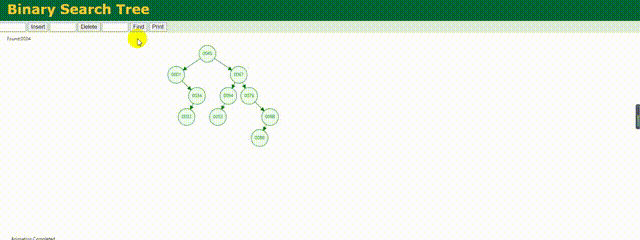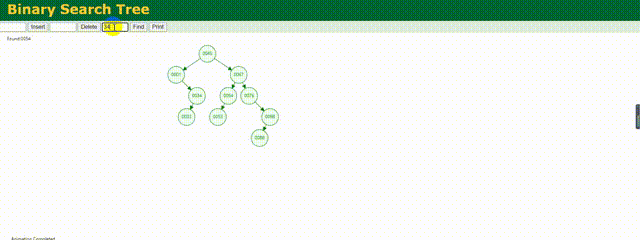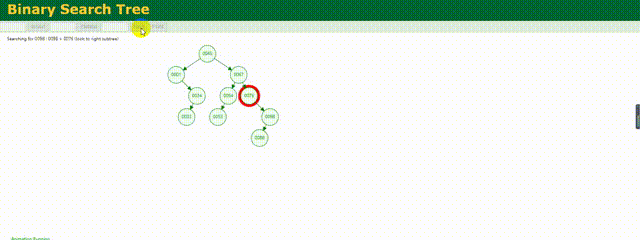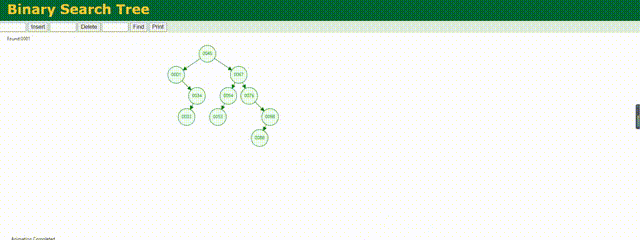
查找流程示例圖:
根據這個動態圖左上角的比對信息,可以很清楚的看到二叉樹的查詢邏輯,感興趣的可以去這個網址實際模擬下:Data Structure Visualization
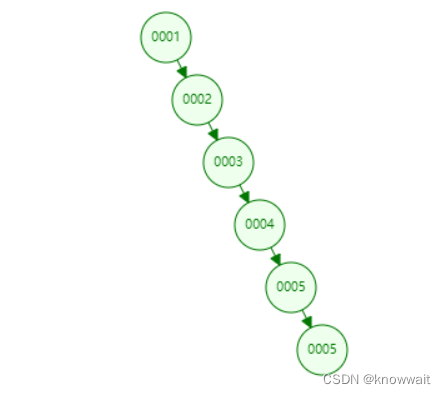
但是上述查詢邏輯是在數據無大小規律存儲的情況下進行查詢的,如果我們的數據按照大小順序存儲會出現以下情況:這其實雖然叫二叉樹但實際上已經是鏈表結構了,假如我們要查詢較為底層的數據,還是要遍歷全局。
MySQL底層不是使用的二叉樹結構。
紅黑樹
相較于上述的二叉樹,紅黑樹做了相應的優化,他會根據存儲的數據動態調整根節點保證樹左右兩邊的平衡,紅黑樹也是一種平衡樹。
下面來動態的看下他是如何存儲數據的:
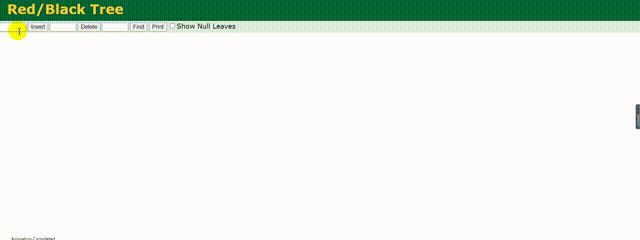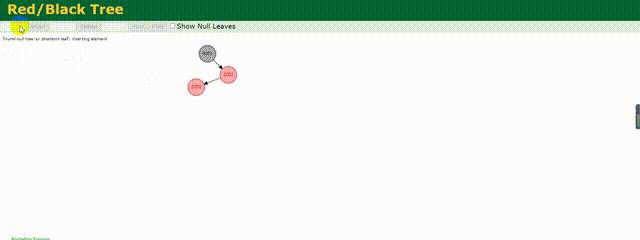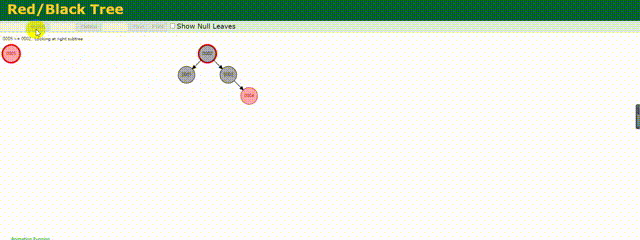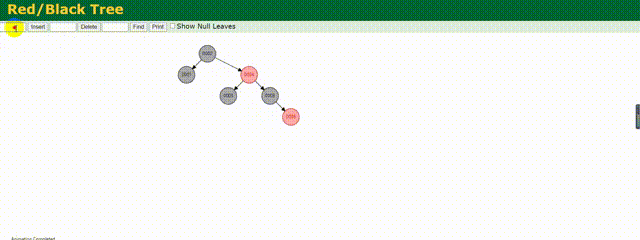
可以明顯的看到他動態調整樹的結構,其實也就是減少了樹的深度,相較于上面變為鏈式的二叉樹,他的效率還是較高的,但是這僅僅適用于數據量不是很大的情況,如果數據量百萬甚至千萬,這個樹的深度一樣很深,查詢起來效率依舊不高。所以MySQL底層也不是使用的紅黑樹結構。
那MySQL使用的那種數據結構來存儲索引數據的呢?
B+Tree
MySQL底層其實是使用的B+Tree的數據結構存儲的
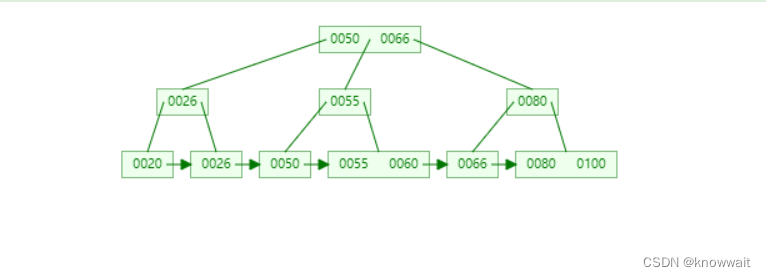
這個結構相對于上述兩種結構都有點復雜了,用更詳細一點的圖來表達可以這么看,他實際上還是樹,但是一個樹節點上不只有一個索引數據,只有最底層的葉子節點上才有數據(這個數據就是我們mysql表中的一列數據或者是mysql數據對應的磁盤地址),而其他節點只存儲索引,也叫作冗余索引。
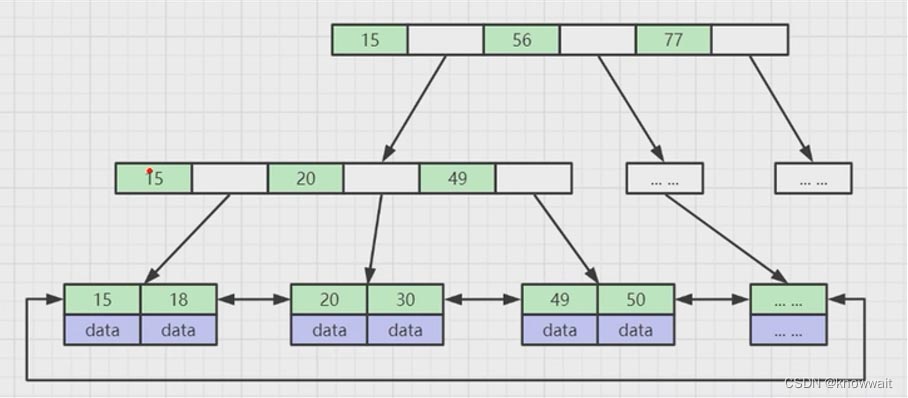
這樣的索引結構有什么好處呢?
在我們創建數據庫索引的時候,他會自動幫我們建立這樣的B+Tree數據結構,上圖假如我們要查詢30那條數據(select * from table where column = 30),這個column就是我們創建索引的那一列,這樣他會把根節點加載到內存中,根據二分法或者其他方式查找到30對應的區間地址,因為在內存中的查找運算要比查詢磁盤要快的多

然后相應的再往下找到30所在的區間位置,遍歷最后一個葉子節點就可以獲取到30那條數據
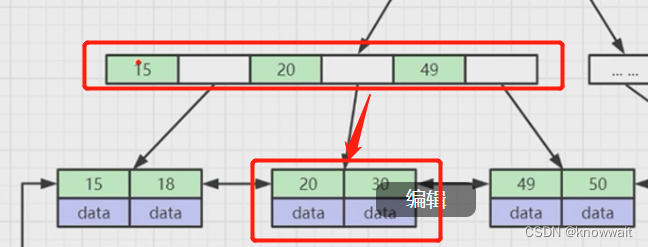
那如果數據量過大,百萬千萬,樹還會不會變得很深?
我們說樹的查詢效率取決于樹的深度,那這個在千萬級數據量下會不會還有二叉樹和紅黑樹一樣的問題呢?
其實沒有了,B+Tree是可以設置樹的最大深度的,我們假設深度設置為3,看看能進行多少量級的數據查詢。
因為在前面的兩層節點中只存儲了索引數據和子節點的磁盤位置,大大節省了存儲空間,每個節點的存儲大小是由mysql設置的分頁參數決定的:一般是16kb
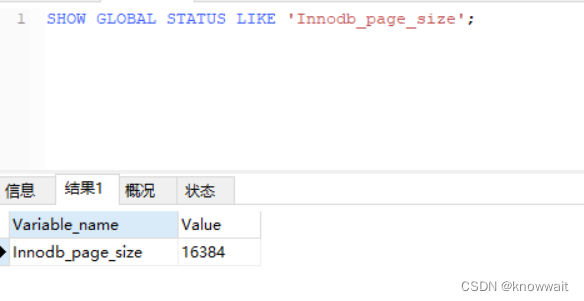
ps:頁是InnoDB訪問的最小單位,默認16KB。緩沖池是以頁為管理單位,每次讀取或刷新一頁數據。參數: innodb_page_size,可以將頁大小設置為4K,8K.
SHOW GLOBAL STATUS LIKE "Innodb_page_size";
而一個索引數據假設我們用的bigInt占用8個字節,兩個索引元素之間的空間是下個節點的磁盤空間地址,占用6個字節,也就是一個索引+節點地址占用14b,那么16kb的空間可以存儲數據量是1170個索引,同理第二個層級的每個節點是也是可以存儲1170個索引,最后一層也就是第三層的節點因為存儲的是實際每一列的數據,假設每列數據占用1kb,那每個節點占存儲16個索引數據。
整個樹的數據存儲量為1170*1170*16=21,902,400,是個兩千萬量級的數據量。完全滿足大數據量的需求。
總結
以上為個人經驗,希望能給大家一個參考,也希望大家多多支持。
相關文章:

 網公網安備
網公網安備