MySQL索引的一些常見面試題大全(2022年)
目錄
- 為什么要建立索引?
- 哪些情況適合建立索引?
- 那么哪些情況下適合建索引?
- 哪些情況下不適合建索引?
- 為什么索引是使用B+樹?(重點)
- 索引分為那幾類?
- 什么是聚簇索引?(重點)
- 使用聚簇索引的優缺點?(知道)
- 為什么推薦使用自增主鍵作為索引?(知道)
- 什么叫回表?(重點)
- 什么叫索引覆蓋?(重點)
- 什么是最左前綴原則?(重點)
- MySQL索引失效的幾種情況(重點)
- 常見的索引優化手段有哪些?
- 談一下你對MySQL索引的理解?
- 總結
為什么要建立索引?
當在非常大的表中進行查詢,如果數據庫進行全表遍歷的話那么速度是會非常慢的,而我們的索引則可以建立一個b+樹的結構,可以自上而下的去進行查詢(有點像二分查找),可以在一定程度避免走全表查詢,這樣查詢的速度是非常快的;
①一般情況下掃描索引的速度是遠遠大于掃描全表的速度的;
②索引是天然有序的,具備B+樹的快速檢索(類似二分查找)
③索引天然聚合(存儲的數據是去重了的),在一些操作(分組,排序等)中不會再產生中間表;
哪些情況適合建立索引?
對于查詢占主要的應用來說,索引顯得尤為重要。很多時候性能問題很簡單的就是因為我們忘了添加索引而造成的,或者說沒有添加更為有效的索引導致。如果不加索引的話,那么查找任何哪怕只是一條特定的數據都會進行一次全表掃描,如果一張表的數據量很大而符合條件的結果又很少,那么不加索引會引起致命的性能下降。但是也不是什么情況都非得建索引不可,比如性別可能就只有兩個值,建索引不僅沒什么優勢,還會影響到更新速度,這被稱為過度索引。
那么哪些情況下適合建索引?
1. 頻繁作為where條件語句查詢的字段
這是因為在頻繁查詢的字段列創建索引可以避免查詢數據的時候走全表掃描,這樣查詢的速度就會大大增加;
2. 關聯字段需要建立索引
關聯的字段一般都是通過主鍵來進行兩張表的關聯,主鍵大部分情況下都是主鍵;如果關聯的兩個主鍵都沒有索引,那么我們一般優先考慮在被驅動表中的字段建立索引,因為在外連接的查詢中被驅動表是需要被多次重復掃描的,那么讓它走索引查詢是會快很多的,可以避免更多次數的全表掃描;
3. 排序字段可以建立索引
這是因為b+樹結構的索引是天然有序的!
4.分組字段可以建立索引,因為分組的前提是排序
5.統計字段可以建立索引,例如count(),max()
這是因為索引是天然聚合的,就是存放在b+樹的數據是已經去重的數據了,存儲的數據還是比較緊湊的,那么通過B+樹的雙向指針可以更快的找到要統計的數據,而且在加了索引的列的統計的時候MySQL是不會產生中間表來專門去重了,可以減少不必要的性能開銷;(在沒有索引的列的統計,分組 的SQL語句中,MySQL都是會創建臨時表來存儲數據的)
哪些情況下不適合建索引?
1.頻繁更新的字段不適合建立索引 (因為數據比較大的表的索引的創建是非常耗時的,而且如果一個字段被頻繁更新那么我們還需要頻繁的維護這個樹的結構,這個開銷是非常大的)
2.參與列計算的列不適合建索引,因為計算后的列的值最后不一定是有序的,不有序那么就會導致索引會失效
3.表數據可以確定比較少的不需要建索引
4.數據重復且分布比較均勻的的字段不適合建索引,因為說不定你對這種索引字段的查詢的速度還沒有全表掃描快,例如性別,真假值;
5.where條件中用不到的字段不適合建立索引,因為索引是可以幫助我們在查詢的時候大大的提高查詢效率,但是在增加,刪除操作確實異常消耗性能的,因為需要不斷的維護B+樹的結構(有序你就需要維護),你查詢的時候都不需要使用到這個字段了,那還建立這個字段的索引列干啥?等著吃你系統的性能嘛?
為什么索引是使用B+樹?(重點)
①因為b+樹是把數據都存放在葉子節點中的(在innodb存儲引擎中一個b+樹的節點是 一頁(16k)),那么在固定大小的容量中 B+樹的非葉子節點中就可以存放更多的索引列數據,也就意味著B+樹的非葉子節點存儲的數據的范圍就會更大,那么樹的層次就會更少,IO次數也就會更少;
②b+樹的葉子節點維護了一個雙向鏈表,它更有利于范圍查詢
③b+樹中的葉子節點和非葉子節點的數據都是分開存儲的,分別存放在葉子節點段和非葉子節點段,那么進行全表掃描的時候,就可以不用再掃描非葉子節點的數據了,并且這是一個順序讀取數據的過程(順序讀比隨機讀的速度要快很多很多),掃描的速度也會大大提高;
索引分為那幾類?
從大類來分:分為聚簇索引和非聚簇索引;
從具體的種類來分有:
主鍵索引: 也簡稱主鍵。它可以提高查詢效率,并提供唯一性約束。一張表中只能有一個主鍵。
普通索引:就是普普通通的索引。
唯一索引:索引的值不能重復。
復合索引:在工作中用得比較頻繁的一個索引;
當有多個查詢條件時,我們推薦使用復合索引。比如:我們經常按照 A列 B列 C列進行查詢時,通常的做法是建立一個由三個列共同組成的復合索引而不是對每一個列建立普通索引。
創建方式: 復合索引中的索引的順序是非常重要的;
alert table test add idx_a1_a2_a3 table (a1,a2,a3)
使用復合索引可以極大的減少回表的帶來的性能開銷;(體現在 復合索引可以進行更多的索引覆蓋(因為你索引的個數明顯更加多了呀),即便是回表也是攜帶更少的主鍵進行回表查詢(與MySQL5.7后的索引下推有關))
復合索引是基于第一個索引的,比如你建立了一個(a,b,c)的復合索引,那么你不能跳過a索引直接去查詢b索引,因為在建立(a,b,c)這個復合索引的時候,是會創建(a),(a,b),(a,b,c)這三個索引的,你會發現它們都是基于a索引的; (并不會單獨的創建(a,c)這個索引)
hash索引:hash天然快(最快o(1),最慢o(n),樹化(lon(n))),但是天然無序;
空間索引;
全文索引;
什么是聚簇索引?(重點)
聚簇索引就是將數據(一行一行的數據)跟索引結構放到一塊,innodb存儲引擎使用的就是聚簇索引;
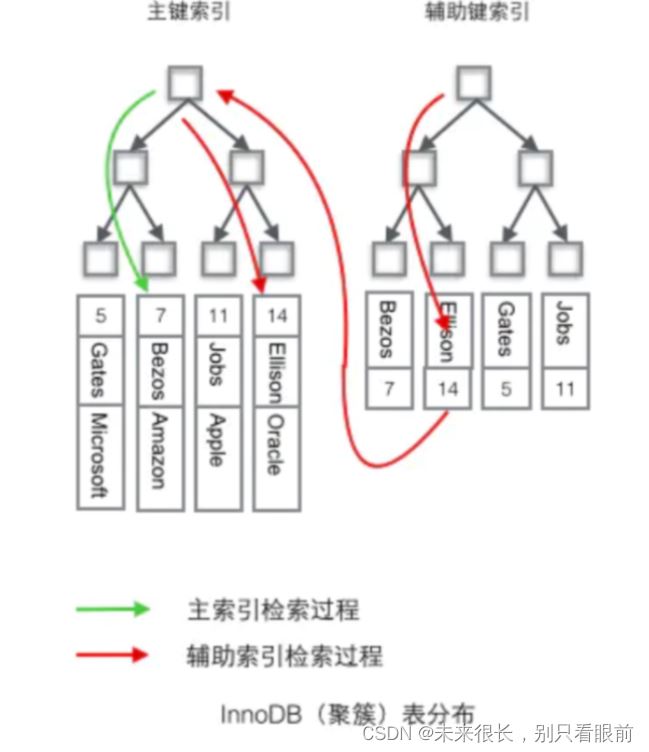
注意點:
- InnoDB使用的是聚簇索引(聚簇索引默認使用主鍵作為其索引),將主鍵組織到一棵B+樹中,而行數據就儲存在葉子節點上,若使用"where id = 14"這樣的條件查找主鍵,則按照B+樹的檢索算法即可查找到對應的葉節點,之后獲得行數據。
- 若對Name列進行條件搜索,則需要兩個步驟:第一步在輔助索引B+樹中檢索Name,到達其葉子節點獲取對應的主鍵。第二步使用主鍵在主索引B+樹種再執行一次B+樹檢索操作,最終到達葉子節點即可獲取整行數據。(重點在于通過其他鍵需要建立輔助索引)
聚簇索引具有唯一性,由于聚簇索引是將數據(一行一行的數據)跟索引結構放到一塊,因此一個表僅有一個聚簇索引,其他輔助索引可能是只有幾個列的數據和索引放在一起!
表中行的物理順序和索引中行的物理順序是相同的,在創建任何非聚簇索引之前創建聚簇索引,這是因為聚簇索引改變了表中行的物理順序,數據行 按照一定的順序排列,并且自動維護(有序就一定需要維護)這個順序;
聚簇索引中的索引默認是主鍵,如果表中沒有定義主鍵,InnoDB 會選擇一個唯一且非空的索引代替。如果沒有這樣的索引,InnoDB 會隱式定義一個6個字節大小的row_id來作為主鍵,這個主鍵會作為聚簇索引中的索引。如果已經設置了主鍵為聚簇索引又希望再單獨設置聚簇索引,必須先刪除主鍵,然后添加我們想要的聚簇索引,最后恢復設置主鍵即可。
使用聚簇索引的優缺點?(知道)
1.由于行數據和聚簇索引的葉子節點存儲在一起,同一頁(16k)中會有多條行數據,訪問同一數據頁不同行記錄時,已經把頁加載到了Buffer中(讀取數據是按頁讀取的),再次訪問時,會在內存中完成訪問,不必訪問磁盤。這樣主鍵和行數據是一起被載入內存的,找到葉子節點就可以立刻將行數據返回了,如果按照主鍵Id來組織數據,獲得數據更快。
2.輔助索引的葉子節點,存儲主鍵值,而不是數據的存放地址。好處是當行數據放生變化時,索引樹的節點也需要分裂變化;或者是我們需要查找的數據,在上一次IO讀寫的緩存中沒有,需要發生一次新的IO操作時,可以避免對輔助索引的維護工作,只需要維護聚簇索引樹就好了。另一個好處是,因為輔助索引存放的是主鍵值,減少了輔助索引占用的存儲空間大小。
注:我們知道一次io讀寫,可以獲取到16K大小的資源,我們稱之為讀取到的數據區域為Page。而我們的B樹,B+樹的索引結構,葉子節點上存放好多個關鍵字(索引值)和對應的數據,都會在一次IO操作中被讀取到緩存中,所以在訪問同一個頁中的不同記錄時,會在內存里操作,而不用再次進行IO操作了。除非發生了頁的分裂,即要查詢的行數據不在上次IO操作的緩存里,才會觸發新的IO操作。
3.因為MyISAM的主索引并非聚簇索引,那么他的數據的物理地址必然是凌亂的,拿到這些物理地址,按照合適的算法進行I/O讀取,于是開始不停的尋道不停的旋轉。聚簇索引則只需一次I/O。(強烈的對比)
4.不過,如果涉及到大數據量的排序、全表掃描、count之類的操作的話,還是MyISAM占優勢些,因為索引所占空間小,這些操作是需要在內存中完成的。
為什么推薦使用自增主鍵作為索引?(知道)
主鍵最好不要使用uuid,因為uuid的值太過離散,不適合排序且可能出現新增加記錄的uuid,會插入在索引樹中間的位置,出現頁分裂(比如之前的索引已經緊湊的排列在一起了,你此時需要在已經緊湊排列好的數據中插入數據就會導致前面已經排好序的索引出現松動和重構排序,但是使用自增id就不會出現這種情況了),導致索引樹調整復雜度變大,消耗更多的時間和資源。但是使用自增主鍵就可以避免出現頁分裂,因為自增主鍵后面的主鍵值是要比前面的大, 那后來的數據直接放在后面就行;
聚簇索引的數據的物理存放順序與索引順序是一致的,即:只要索引是相鄰的,那么對應的數據一定也是相鄰地存放在磁盤上的。如果主鍵不是自增id,它會不斷地調整數據的物理地址、分頁,當然也有其他一些措施來減少這些操作,但卻無法徹底避免。但如果是自增的id,它只需要一 頁一頁地寫,索引結構相對緊湊,磁盤碎片少,效率也高。
什么叫回表?(重點)
如果一個查詢是先走輔助索引(聚簇索引外的索引都叫輔助索引)的,那么通過這個輔助索引(innodb中的輔助索引的data存儲的是主鍵)沒有獲取到我們想要的全部數據,那么MySQL就會拿著輔助索引查詢出來的主鍵去聚簇索引中進行查詢,這個過程就是叫回表;
什么叫索引覆蓋?(重點)
如果一個查詢是先走輔助索引的,那么通過這個輔助索引就直接獲取到我們想要的全部數據了,不需要進行回表,這個過程就叫做索引覆蓋;
什么是最左前綴原則?(重點)
大白話就是 從最左的索引開始匹配,遇到范圍查詢就會讓后面范圍列后的索引失效;
mysql會一直向右匹配直到遇到范圍查詢(>、<、between、like)就停止匹配,比如a = 1 and b = 2 and c > 3 and d = 4 ,如果建立(a,b,c,d)順序的聯合索引,d是用不到索引的,如果建立(a,b,d,c)的索引則都可以用到,a,b,d的順序可以任意調整。
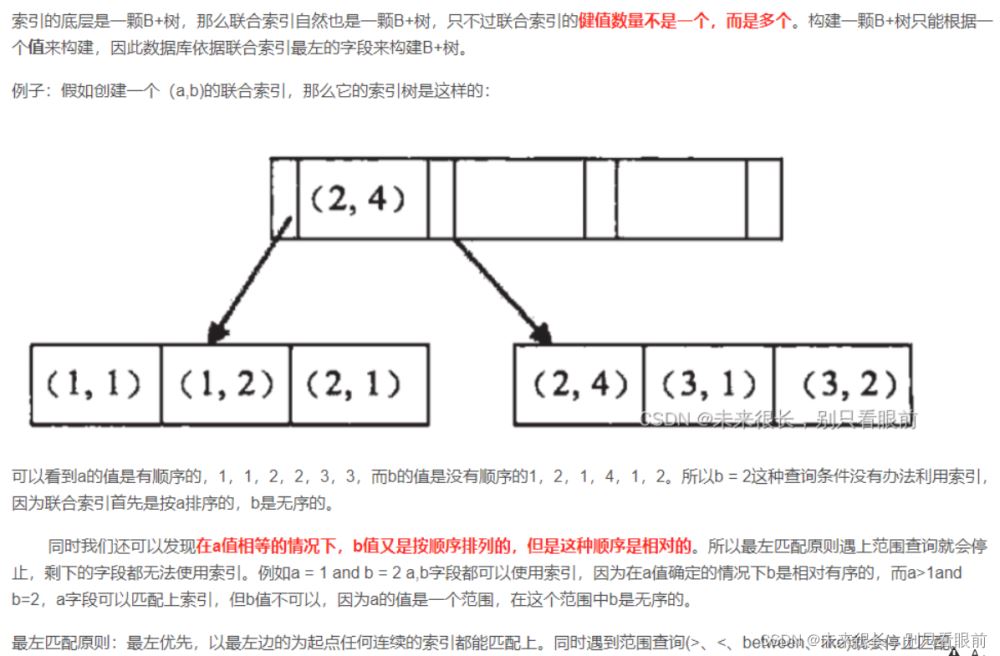
了解一下:
在MySQL5.6及5.6以前,最左匹配就是只有最左道索引會生效;(這個時候創建復合索引是為了避免回表)
在MySQL5.7最左匹配引入了索引下推, 比如創建(a,b,c)的復合索引,在進行where a=xxx and b=xxx and c=xxx 的查詢語句中,MySQL是先在索引中找到滿足a條件的數據,然后再在a中取滿足b的條件,然后再在b中取滿足c的數據,最后再拿著非常少的主鍵到聚簇索引中查詢最后的行數據;
比如:有1000W條數據的表,有如下sql:select from table where a =1 and b =2 and c =3,假設假設每個條件可以篩選出10%的數據,如果只有單值索引,那么通過該索引能篩選出1000W10%=100w條數據,然后再回表從100w條數據中找到符合b =2 and c = 3的數據,然后再排序,再分頁;如果是聯合索引,通過索引篩選出1000w10% 10% *10%=1w,效率提升可想而知!
MySQL索引失效的幾種情況(重點)
①like查詢以%開頭,因為會導致查詢出來的結果無序;
②類型轉換,列計算也會可能會讓索引失效,因為結果可能是無序的,也可能是有序的;
③在一些查詢的語句中,MySQL認為走全表掃描比索引更加快也會導致索引失效;
④如果條件中有or并且or連接的字段中有列沒有索引,那么即使其中有條件帶索引也不會使用索引 (這是因為MySQL判斷即便你開始走了索引查詢,但是它發現查詢中有Or ,也就是說or 后面的還是需要走全表掃描(因為or會導致后面的數據是無序的),所以MySQL還不如一開始就直接走全表掃描,這也是為什么盡量少用or的原因)要想使用or,又想讓索引生效,只能將or條件中的每個列都加上索引,當檢索條件有or但是所有的條件都有索引時,索引不失效,可以走【兩個索引】,這叫索引合并(取二者的并集);
⑤復合索引不滿足最左原則就不能使用全部索引
常見的索引優化手段有哪些?
① 盡可能的使用復合索引而不是索引的組合;
②創建索引盡量讓輔助索引進行索引覆蓋 而不是回表;
③在可以使用主鍵id的表中,盡量使用自增主鍵id,這樣可以避免頁分裂;
④查詢的時候盡量不要使用select * ,這樣可以避免大量的回表;
⑤盡量少使用子查詢,能使用外連接就使用外連接,這樣可以避免產生笛卡爾集;
⑥能使用短索引就是用短索引,這樣可以在非葉子節點存儲更多的索引列降低樹的層高,并且減少空間的開銷;
談一下你對MySQL索引的理解?
索引的b+樹結構,為什么使用b+樹說一下,然后再說一下聚簇索引,回表和索引覆蓋;
然后再談一下索引失效;
總結
到此這篇關于MySQL索引的一些常見面試題大全的文章就介紹到這了,更多相關MySQL索引面試題內容請搜索以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持!
 網公網安備
網公網安備