mysql中的utf8與utf8mb4存儲及區別
目錄
- 一、如何設置utf8mb4
- 二、問題
- 1、為什么存儲的時候要區分utf8和utf8mb4
- 2、為什么讀取的時候要區分utf8和utf8mb4
一、如何設置utf8mb4
mysql中針對字符串類型,在設置charset的時候可以精確到字段。
如果只將某個字段設置utf8mb4,那么其他字段不會受影響。
如果針對表來設置,那么已經存在的字段依然是utf8,并且會多出utf8的標記,之后所創建的字段才會是utf8mb4。
如果針對庫來設置,那么已經存在的表依然是utf8,之后所創建的表才會是utf8mb4。
除此之外呢,我們在連接數據庫的時候,也要指明charset=utf8mb4,否則的話,此連接無法向utf8mb4的字段寫入數據,并且讀取的時候是亂碼。
在使用 navicat 的時候,發現沒有地方設置連接的字符編碼,他會自動掃面你的數據庫,表,字段的編碼,來自動設置一個合適的編碼,當然,這也跟 navicat 版本有關,高版本才行,我的低版本就不行,如果你發現你的 navicat 無法顯示表情,只能看到問好,那么可以通過show variables like '%char%'查看一下。
我還遇到一個情況,我的 navicat 沒法自動設置 utf8mb4,因此,在 utf8 的情況下,我將線上的表情同步到了我本地,這使得我在后面即使設置了 utf8mb4 的情況下也看不到表情,這是因為我在 utf8 的時候同步過來的數據被破壞了,字符集不兼容,所以需要先設置好字符編碼再拉取一次數據。
二、問題
1、為什么存儲的時候要區分utf8和utf8mb4
按理說,不管我存進去的是單字節還是多字節,本質都是二進制,我寫入什么你就存什么不就好了,干嘛還要有限制。這是因為,Mysql對每個字段都定義了長度,比如varchar(10)表示10個字符,而不是字節,所以當存入數據的時候,mysql是做了解析的,這樣才能知道字符串里有幾個字符;當面對4字節字符的時候,mysql依然會以3字節的編碼規則來解析,顯然會解析出錯的,因此就不讓寫入。
MySQL在5.5.3之后增加了這個utf8mb4的編碼,mb4就是most bytes 4的意思,專門用來兼容四字節的unicode。好在 utf8mb4 是 utf8 的超集,除了將編碼改為 utf8mb4 外不需要做其他轉換。當然,為了節省空間,一般情況下使用 utf8 也就夠了。
utf8 是 Mysql 中的一種字符集,只支持最長三個字節的 UTF-8 字符,可能是因為 Mysql 剛開始開發那會,Unicode 還沒有4字節的字符。至于后續的版本為什么不對 4 字節長度的 UTF-8 字符提供支持,應該是為了向后兼容性的考慮,還有就是4字節字符確實很少用到。
2、為什么讀取的時候要區分utf8和utf8mb4
按理說,我讀取的都是二進制,不管是三字節還是四字節,我自己來展示,為什么在讀取 utf8mb4 字段的時候,我使用 utf8 的連接得到的是亂碼,使用 utf8mb4 連接得到的是正常的。實際上我的電腦是能展示四字節字符的。
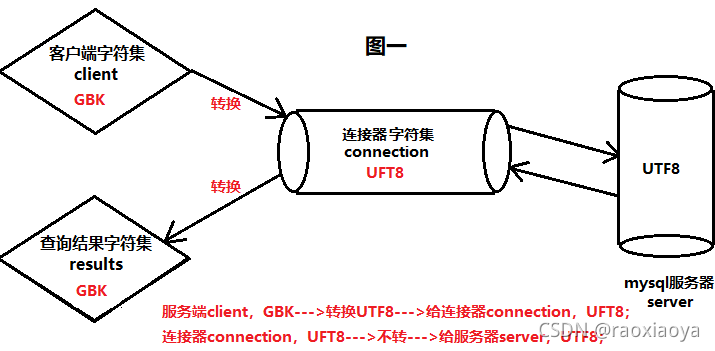
因為mysql有個連接器組件,它處于客戶端和服務器之間,用于字符集的轉換。
現在有一個字段name,為了兼容emoj表情,字段設置為utf8mb4,在寫入的時候數據庫連接設置了charset=utf8mb4,因此可以正常寫入;在讀取的時候數據庫連接設置charset=utf8,于是讀出來展示的時候是亂碼,如果改成charset=utf8mb4,讀出來就能正常展示,那就是說,utf8的連接讀到的結果并不是真實的數據,而是經過了連接器的轉換,它將utf8mb4轉換成了utf8,四字節字符被轉換成了三字節,自然就是亂碼。
那么,為什么要有這個轉碼的過程呢?
那是因為mysql支持很多的字符編碼。
mysql> show character set;+----------+-----------------------------+---------------------+--------+| Charset | Description | Default collation | Maxlen |+----------+-----------------------------+---------------------+--------+| big5 | Big5 Traditional Chinese | big5_chinese_ci | 2 || dec8 | DEC West European | dec8_swedish_ci | 1 || cp850 | DOS West European | cp850_general_ci | 1 || hp8 | HP West European | hp8_english_ci | 1 || koi8r | KOI8-R Relcom Russian | koi8r_general_ci | 1 || latin1 | cp1252 West European| latin1_swedish_ci | 1 || latin2 | ISO 8859-2 Central European | latin2_general_ci | 1 || swe7 | 7bit Swedish| swe7_swedish_ci | 1 || ascii | US ASCII | ascii_general_ci | 1 || ujis | EUC-JP Japanese | ujis_japanese_ci | 3 || sjis | Shift-JIS Japanese | sjis_japanese_ci | 2 || hebrew | ISO 8859-8 Hebrew | hebrew_general_ci | 1 || tis620 | TIS620 Thai | tis620_thai_ci | 1 || euckr | EUC-KR Korean | euckr_korean_ci | 2 || koi8u | KOI8-U Ukrainian | koi8u_general_ci | 1 || gb2312 | GB2312 Simplified Chinese | gb2312_chinese_ci | 2 || greek | ISO 8859-7 Greek | greek_general_ci | 1 || cp1250 | Windows Central European | cp1250_general_ci | 1 || gbk | GBK Simplified Chinese | gbk_chinese_ci | 2 || latin5 | ISO 8859-9 Turkish | latin5_turkish_ci | 1 || armscii8 | ARMSCII-8 Armenian | armscii8_general_ci | 1 || utf8 | UTF-8 Unicode | utf8_general_ci | 3 || ucs2 | UCS-2 Unicode | ucs2_general_ci | 2 || cp866 | DOS Russian | cp866_general_ci | 1 || keybcs2 | DOS Kamenicky Czech-Slovak | keybcs2_general_ci | 1 || macce | Mac Central European| macce_general_ci | 1 || macroman | Mac West European | macroman_general_ci | 1 || cp852 | DOS Central European| cp852_general_ci | 1 || latin7 | ISO 8859-13 Baltic | latin7_general_ci | 1 || utf8mb4 | UTF-8 Unicode | utf8mb4_general_ci | 4 || cp1251 | Windows Cyrillic | cp1251_general_ci | 1 || utf16 | UTF-16 Unicode | utf16_general_ci | 4 || utf16le | UTF-16LE Unicode | utf16le_general_ci | 4 || cp1256 | Windows Arabic | cp1256_general_ci | 1 || cp1257 | Windows Baltic | cp1257_general_ci | 1 || utf32 | UTF-32 Unicode | utf32_general_ci | 4 || binary | Binary pseudo charset | binary | 1 || geostd8 | GEOSTD8 Georgian | geostd8_general_ci | 1 || cp932 | SJIS for Windows Japanese | cp932_japanese_ci | 2 || eucjpms | UJIS for Windows Japanese | eucjpms_japanese_ci | 3 |+----------+-----------------------------+---------------------+--------+40 rows in set
collation為排序規則,Maxlen為最大字節數。
不同的編碼規則,會得到不同的二進制數,因此正確的編碼轉換是必要的。
查看當前的編碼
mysql> show variables like "%char%";+--------------------------+--------+| Variable_name | Value |+--------------------------+--------+| character_set_client | utf8 || character_set_connection | utf8 || character_set_database | utf8 || character_set_filesystem | binary || character_set_results | utf8 || character_set_server | utf8 || character_set_system | utf8 || character_sets_dir ||+--------------------------+--------+
設置當前連接的編碼,只針對此連接有效
mysql -h xxxxxx.mysql.rds.aliyuncs.com -u xxxxxx -p xxxxxxmysql> set names gbk;mysql> show variables like "%char%";+--------------------------+--------+| Variable_name | Value |+--------------------------+--------+| character_set_client | gbk || character_set_connection | gbk || character_set_database | utf8 || character_set_filesystem | binary || character_set_results | gbk || character_set_server | utf8 || character_set_system | utf8 || character_sets_dir ||+--------------------------+--------+
這個命令會同時修改character_set_client, character_set_connection, character_set_results
我們在接數據庫的時候設置的charset=utf8在內部就是調用的set names utf8。
所以,代表客戶端的編碼有三個,這三個編碼基本是一致的。其他的都是服務端的的編碼。
character_set_client 客戶端
character_set_connection 連接器
character_set_results 返回的結果集
既然是一樣的,為什么客戶端要搞三個配置呢,這就要從數據傳輸的流程上來看。
連接器:連接客戶端與服務端,進行字符集的轉換。
連接器的工作流程:
請求
character_set_client --> character_set_connection -->character_set_server
響應
character_set_server --> character_set_connection --> character_set_results
圖示
到此這篇關于mysql中的utf8與utf8mb4存儲及區別的文章就介紹到這了,更多相關mysql utf8與utf8mb4內容請搜索以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持!

 網公網安備
網公網安備