Python文件名的匹配之clob庫
既然在Pathlib庫中提到了glob()函數,那么我們就專門用一篇內容講解文件名的匹配。其實我們有專門的一個文件名匹配庫就叫:glob。
不過,glob庫的API非常小,但是僅僅應用于文件名的匹配綽綽有余。只要是在實際的項目中需要過濾,或者匹配一組文件,都可以使用該庫進行操作。
二、通配符星號(*)
話不多說,下面我們使用通配符來匹配文件名,示例如下:
import globfor name in sorted(glob.glob(’text/*’)): print(name)
運行之后,效果如下:
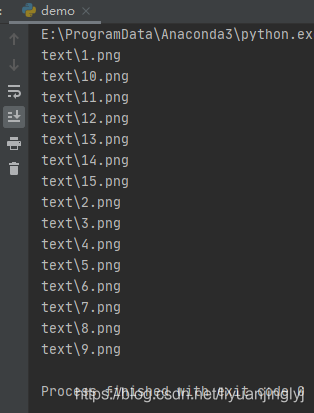
這里不僅用*通配符獲取了目錄下的所有文件,而且還對其進行了排序。
三、問號(?)問號(?)是用來匹配單字的,比如我們賽選上面1開頭的圖片文件。示例如下:
import globfor name in glob.glob(’text/1?.png’): print(name)
運行之后,效果如下:
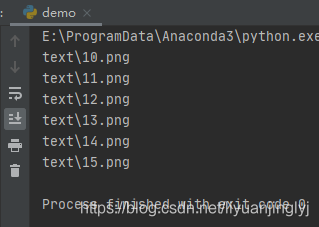
從上面兩個匹配我們看出來,glob庫的匹配規則與正則表達式有些相似。既然它能匹配模糊的,一個或多個字符,那么肯定也可以匹配區間字符。
示例如下:
import globfor name in glob.glob(’text/15[a-z].*’): print(name)
運行之后,效果如下:
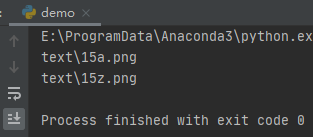
當然,上面的文件名都是常規的文件名,都是用字母與數字組成的。但是,有些人比較怪,可能在文件名中包含了特殊的字符,比如上面的匹配字符“?*[”等。那怎么辦呢?用反斜杠“”轉義嗎?
其實,我們還有更簡單的,直接使用escape()函數進行操作。示例如下:
import globescape_str=’?*[]’for char in escape_str: pattern = ’text/*’ + glob.escape(char) + ’.png’ for name in glob.glob(pattern):print(name)
運行之后,效果如下:
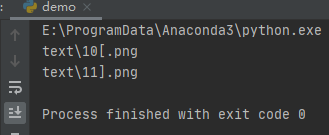
到此這篇關于Python文件名的匹配之clob庫的文章就介紹到這了,更多相關Python lob庫內容請搜索好吧啦網以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持好吧啦網!
相關文章:
 網公網安備
網公網安備