一文解開java中字符串編碼的小秘密(干貨)
簡介
在本文中你將了解到Unicode和UTF-8,UTF-16,UTF-32的關系,同時你還會了解變種UTF-8,并且探討一下UTF-8和變種UTF-8在java中的應用。
一起來看看吧。
Unicode的發展史
在很久很久以前,西方世界出現了一種叫做計算機的高科技產品。
初代計算機只能做些簡單的算數運算,還要使用人工打孔的程序才能運行,不過隨著時間的推移,計算機的體積越來越小,計算能力越來越強,打孔已經不存在了,變成了人工編寫的計算機語言。
一切都在變化,唯有一件事情沒有變化。這件事件就是計算機和編程語言只流傳在西方。而西方日常交流使用26個字母加有限的標點符號就夠了。
最初的計算機存儲可以是非常昂貴的,我們用一個字節也就是8bit來存儲所有能夠用到的字符,除了最開始的1bit不用以外,總共有128中選擇,裝26個小寫+26個大寫字母和其他的一些標點符號之類的完全夠用了。
這就是最初的ASCII編碼,也叫做美國信息交換標準代碼(American Standard Code for Information Interchange)。
后面計算機傳到了全球,人們才發現好像之前的ASCII編碼不夠用了,比如中文中常用的漢字就有4千多個,怎么辦呢?
沒關系,將ASCII編碼本地化,叫做ANSI編碼。1個字節不夠用就用2個字節嘛,路是人走出來的,編碼也是為人來服務的。于是產生了各種如GB2312, BIG5, JIS等各自的編碼標準。這些編碼雖然與ASCII編碼兼容,但是相互之間卻并不兼容。
這嚴重的影響了國際化的進程,這樣還怎么去實現同一個地球,同一片家園的夢想?
于是國際組織出手了,制定了UNICODE字符集,為所有語言的所有字符都定義了一個唯一的編碼,unicode的字符集是從U+0000到U+10FFFF這么多個編碼。
那么unicode和UTF-8,UTF-16,UTF-32有什么關系呢?
unicode字符集最后是要存儲到文件或者內存里面的,直接存儲的話,空間占用太大。那怎么存呢?使用固定的1個字節,2個字節還是用變長的字節呢?于是我們根據編碼方式的不同,分成了UTF-8,UTF-16,UTF-32等多種編碼方式。
其中UTF-8是一種變長的編碼方案,它使用1-4個字節來存儲。UTF-16使用2個或者4個字節來存儲,JDK9之后的String的底層編碼方式變成了兩種:LATIN1和UTF16。
而UTF-32是使用4個字節來存儲。這三種編碼方式中,只有UTF-8是兼容ASCII的,這也是為什么國際上UTF-8編碼方式比較通用的原因(畢竟計算機技術都是西方人搞出來的)。
Unicode詳解
知道了Unicode的發展史之后,接下來我們詳解講解一下Unicode到底是怎么編碼的。
Unicode標準從1991年發布1.0版本,已經發展到2020年3月最新的13.0版本。
Unicode能夠表示的字符串范圍是0到10FFFF,表示為U+0000到U+10FFFF。
其中U+D800到U+DFFF的這些字符是預留給UTF-16使用的,所以Unicode的實際表示字符個數是216 − 211 + 220 = 1,112,064個。
我們將Unicode的這些字符集分成17個平面,各個平面的分布圖如下:
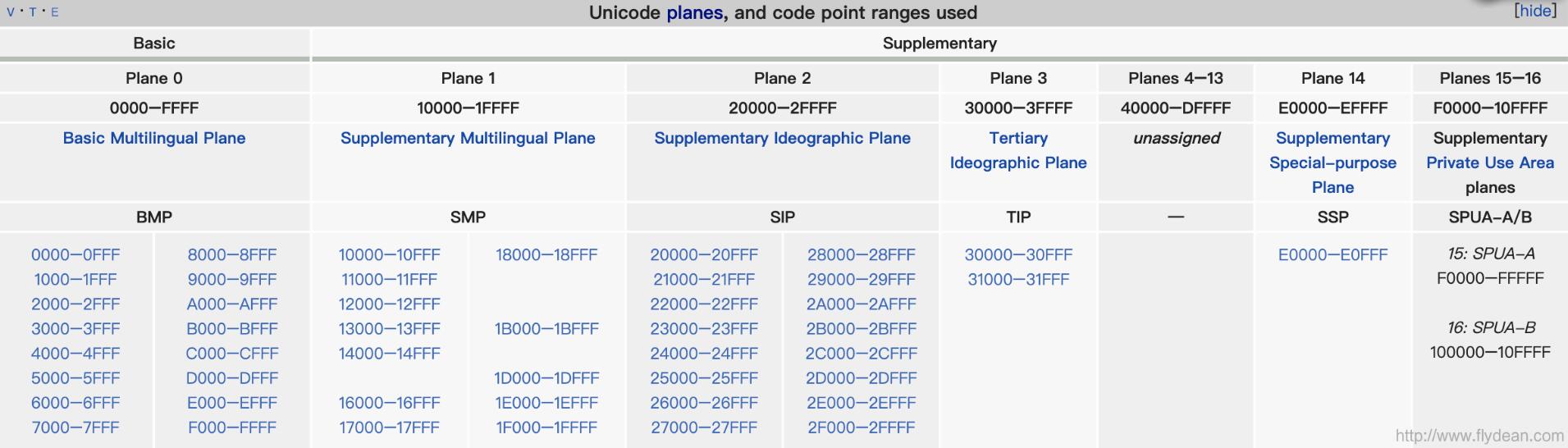
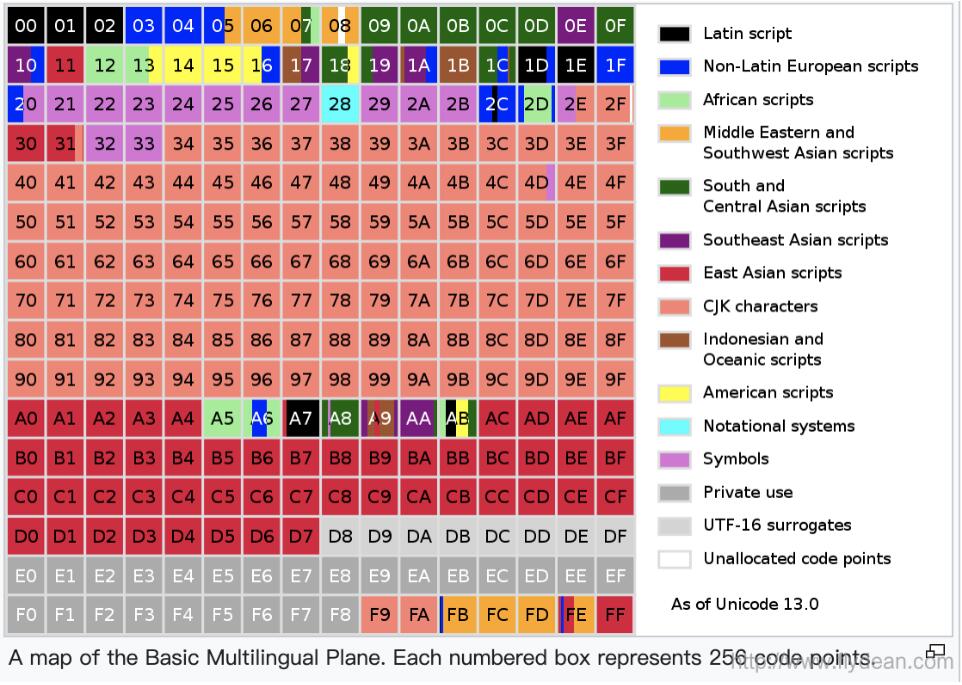
以Plan 0為例,Basic Multilingual Plane (BMP)基本上包含了大部分常用的字符,下圖展示了BMP中所表示的對應字符:
上面我們提到了U+D800到U+DFFF是UTF-16的保留字符。其中高位U+D800?U+DBFF和低位U+DC00?U+DFFF是作為一對16bits來對非BMP的字符進行UTF-16編碼。單獨的一個16bits是無意義的。
UTF-8
UTF-8是用1到4個字節來表示所有的1,112,064個Unicode字符。所以UTF-8是一種變長的編碼方式。
UTF-8目前是Web中最常見的編碼方式,我們看下UTF-8怎么對Unicode進行編碼:
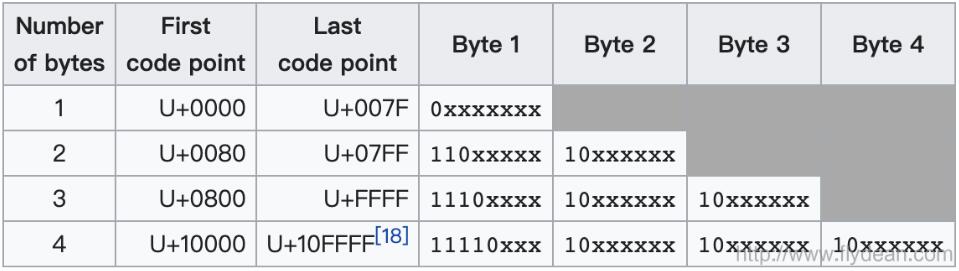
最開始的1個字節可以表示128個ASCII字符,所以UTF-8是和ASCII兼容的。
接下來的1,920個字符需要兩個字節進行編碼,涵蓋了幾乎所有拉丁字母字母表的其余部分,以及希臘語,西里爾字母,科普特語,亞美尼亞語,希伯來語,阿拉伯語,敘利亞語,Thaana和N’Ko字母,以及組合變音符號標記。BMP中的其余部分中的字符需要三個字節,其中幾乎包含了所有常用字符,包括大多數中文,日文和韓文字符。Unicode中其他平面中的字符需要四個字節,其中包括不太常見的CJK字符,各種歷史腳本,數學符號和表情符號(象形符號)。
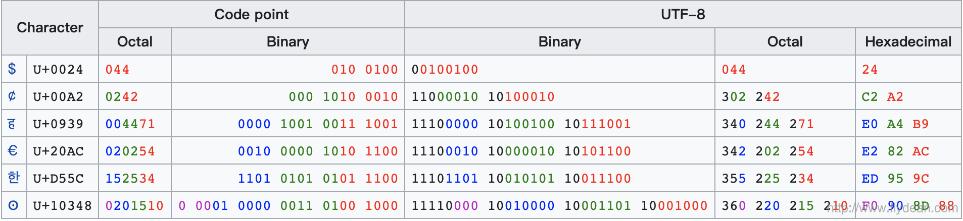
下面是一個具體的UTF-8編碼的例子:
UTF-16
UTF-16也是一種變長的編碼方式,UTF-16使用的是1個到2個16bits來表示相應的字符。
UTF-16主要在Microsoft Windows, Java 和 JavaScript/ECMAScript內部使用。
不過UTF-16在web上的使用率并不高。
接下來,我們看一下UTF-16到底是怎么進行編碼的。
首先:U+0000 to U+D7FF 和 U+E000 to U+FFFF,這個范圍的字符,直接是用1個16bits來表示的,非常的直觀。
接著是:U+010000 to U+10FFFF
這個范圍的字符,首先減去0x10000,變成20bits表示的0x00000?0xFFFFF。
然后高10bits位的0x000?0x3FF加上0xD800,變成了0xD800?0xDBFF,使用1個16bits來表示。
低10bits的0x000?0x3FF加上0xDC00,變成了0xDC00?0xDFFF,使用1個16bits來表示。
U’ = yyyyyyyyyyxxxxxxxxxx // U - 0x10000
W1 = 110110yyyyyyyyyy // 0xD800 + yyyyyyyyyy
W2 = 110111xxxxxxxxxx // 0xDC00 + xxxxxxxxxx
這也是為什么在Unicode中0xD800?0xDFFF是UTF-16保留字符的原因。
下面是一個UTF-16編碼的例子:

UTF-32
UTF-32是固定長度的編碼,每一個字符都需要使用1個32bits來表示。
因為是32bits,所以UTF-32可以直接用來表示Unicode字符,缺點就是UTF-32占用的空間太大,所以一般來說很少有系統使用UTF-32.
Null-terminated string 和變種UTF-8
在C語言中,一個string是以null character (’0’)NUL結束的。
所以在這種字符中,0x00是不能存儲在String中間的。那么如果我們真的想要存儲0x00該怎么辦呢?
我們可以使用變種UTF-8編碼。
在變種UTF-8中,null character (U+0000) 是使用兩個字節的:11000000 10000000 來表示的。
所以變種UTF-8可以表示所有的Unicode字符,包括null character U+0000。
通常來說,在java中,InputStreamReader 和 OutputStreamWriter 默認使用的是標準的UTF-8編碼,但是在對象序列化和DataInput,DataOutput,JNI和class文件中的字符串常量都是使用的變種UTF-8來表示的。
補充知識:Java基礎之字符串的編碼(Encode)和解碼(Decode)
廢話不多說,看代碼~
package newFeatures8; import java.io.UnsupportedEncodingException;import java.util.Arrays; /* * 編碼(由看得懂到看不懂):字符串變字節數組 * 解碼(由看不懂到看得懂):字符數組變字符串 * String--》byte[];//str.getBytes();//str.getBytes(String CharsetName); * byte[]--》String;//new String(byte[] bytes)//new String(byte[] bytes,String CharsetName); */ public class Practice { public static void main(String[] args) {try { String s='你好'; //ISO-8859-1 根本就不識別中文 // byte[] bytes=s.getBytes('gbk'); // System.out.println(Arrays.toString(bytes));//[-60, -29, -70, -61] //使用utf-8 編碼每個字符占3個字節 //byte[] bytes=s.getBytes('utf-8'); // System.out.println(Arrays.toString(bytes));//[-28, -67, -96, -27, -91, -67] // String s1=new String(s.getBytes('utf-8'), 'gbk');//浣?濂 // String s1=new String(s.getBytes('gbk'), 'utf-8');//??? //當網頁已經出現亂碼,而使用的Tomcat服務器,Tomcat服務器使用的是ISO-8859-1 只需要再編碼解碼即可 String s1=new String(s.getBytes('ISO-8859-1'), 'utf-8'); System.out.println(s1); //一般要養成一個習慣:就是全部用utf-8} catch (UnsupportedEncodingException e) {e.printStackTrace();} } }
package newFeatures8; import java.io.UnsupportedEncodingException; public class Practice {public static void main(String[] args) throws UnsupportedEncodingException {getLowest8Bit();}/* * 通過研究發現:當往記事本里寫入'聯通'兩字時,保存后打開,發現出現亂碼 * 原因是:當你寫入中文時:記事本使用的是GBK(按照一個字符兩個字節)編碼 * ,當你打開記事本時,使用的是UTF-8(按照一個字符3個字節)解碼 * 如何解決:只要在聯通前加個漢字即可,不能是字母 * * '聯通'二字比較特殊 * 其二進制數的最低8位剛好符合UTF-8的解碼格式 */public static void getLowest8Bit() throws UnsupportedEncodingException{String s='聯通';byte[] bytes=s.getBytes('gbk');for (byte b : bytes) {//System.out.println(Integer.toBinaryString(b));/* 11111111111111111111111111000001111111111111111111111111101010101111111111111111111111111100110111111111111111111111111110101000 *///通過使用 與上 &0xff 來獲取其最低最低8位 0xff=255System.out.println(Integer.toBinaryString(b&0xff));/* * 11000001101010101100110110101000 *///匹配到了utf-8 的標志位//一個字節 標志位0打頭//兩個字節 :第一個字節110打頭,第二個字節10打頭//三個字節:第一個字節1110打頭,第二個字節10打頭,第三個字節10打頭}}}
以上這篇一文解開java中字符串編碼的小秘密(干貨)就是小編分享給大家的全部內容了,希望能給大家一個參考,也希望大家多多支持好吧啦網。
相關文章:
 網公網安備
網公網安備