Java實現雪花算法的原理
SnowFlake 算法,是 Twitter 開源的分布式 id 生成算法。其核心思想就是:使用一個 64 bit 的 long 型的數字作為全局唯一 id。在分布式系統中的應用十分廣泛,且ID 引入了時間戳,基本上保持自增的,后面的代碼中有詳細的注解。
這 64 個 bit 中,其中 1 個 bit 是不用的,然后用其中的 41 bit 作為毫秒數,用 10 bit 作為工作機器 id,12 bit 作為序列號。

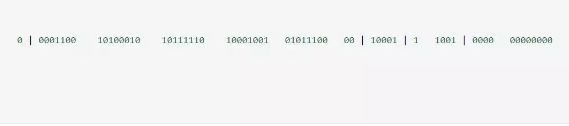
給大家舉個例子吧,比如下面那個 64 bit 的 long 型數字:
第一個部分,是 1 個 bit:0,這個是無意義的。 第二個部分是 41 個 bit:表示的是時間戳。 第三個部分是 5 個 bit:表示的是機房 id,10001。 第四個部分是 5 個 bit:表示的是機器 id,1 1001。 第五個部分是 12 個 bit:表示的序號,就是某個機房某臺機器上這一毫秒內同時生成的 id 的序號,0000 00000000。①1 bit:是不用的,為啥呢?
因為二進制里第一個 bit 為如果是 1,那么都是負數,但是我們生成的 id 都是正數,所以第一個 bit 統一都是 0。
②41 bit:表示的是時間戳,單位是毫秒。
41 bit 可以表示的數字多達 2^41 - 1,也就是可以標識 2 ^ 41 - 1 個毫秒值,換算成年就是表示 69 年的時間。
③10 bit:記錄工作機器 id,代表的是這個服務最多可以部署在 2^10 臺機器上,也就是 1024 臺機器。
但是 10 bit 里 5 個 bit 代表機房 id,5 個 bit 代表機器 id。意思就是最多代表 2 ^ 5 個機房(32 個機房),每個機房里可以代表 2 ^ 5 個機器(32 臺機器),也可以根據自己公司的實際情況確定。
④12 bit:這個是用來記錄同一個毫秒內產生的不同 id。
12 bit 可以代表的最大正整數是 2 ^ 12 - 1 = 4096,也就是說可以用這個 12 bit 代表的數字來區分同一個毫秒內的 4096 個不同的 id。
簡單來說,你的某個服務假設要生成一個全局唯一 id,那么就可以發送一個請求給部署了 SnowFlake 算法的系統,由這個 SnowFlake 算法系統來生成唯一 id。
這個 SnowFlake 算法系統首先肯定是知道自己所在的機房和機器的,比如機房 id = 17,機器 id = 12。
接著 SnowFlake 算法系統接收到這個請求之后,首先就會用二進制位運算的方式生成一個 64 bit 的 long 型 id,64 個 bit 中的第一個 bit 是無意義的。
接著 41 個 bit,就可以用當前時間戳(單位到毫秒),然后接著 5 個 bit 設置上這個機房 id,還有 5 個 bit 設置上機器 id。
最后再判斷一下,當前這臺機房的這臺機器上這一毫秒內,這是第幾個請求,給這次生成 id 的請求累加一個序號,作為最后的 12 個 bit。
最終一個 64 個 bit 的 id 就出來了,類似于:
這個算法可以保證說,一個機房的一臺機器上,在同一毫秒內,生成了一個唯一的 id。可能一個毫秒內會生成多個 id,但是有最后 12 個 bit 的序號來區分開來。
下面我們簡單看看這個 SnowFlake 算法的一個代碼實現,這就是個示例,大家如果理解了這個意思之后,以后可以自己嘗試改造這個算法。
總之就是用一個 64 bit 的數字中各個 bit 位來設置不同的標志位,區分每一個 id。
SnowFlake 算法的實現代碼如下:
public class IdWorker { //因為二進制里第一個 bit 為如果是 1,那么都是負數,但是我們生成的 id 都是正數,所以第一個 bit 統一都是 0。 //機器ID 2進制5位 32位減掉1位 31個private long workerId;//機房ID 2進制5位 32位減掉1位 31個private long datacenterId;//代表一毫秒內生成的多個id的最新序號 12位 4096 -1 = 4095 個private long sequence;//設置一個時間初始值 2^41 - 1 差不多可以用69年private long twepoch = 1585644268888L;//5位的機器idprivate long workerIdBits = 5L;//5位的機房idprivate long datacenterIdBits = 5L;//每毫秒內產生的id數 2 的 12次方private long sequenceBits = 12L;// 這個是二進制運算,就是5 bit最多只能有31個數字,也就是說機器id最多只能是32以內private long maxWorkerId = -1L ^ (-1L << workerIdBits);// 這個是一個意思,就是5 bit最多只能有31個數字,機房id最多只能是32以內private long maxDatacenterId = -1L ^ (-1L << datacenterIdBits); private long workerIdShift = sequenceBits;private long datacenterIdShift = sequenceBits + workerIdBits;private long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;private long sequenceMask = -1L ^ (-1L << sequenceBits);//記錄產生時間毫秒數,判斷是否是同1毫秒private long lastTimestamp = -1L;public long getWorkerId(){return workerId;}public long getDatacenterId() {return datacenterId;}public long getTimestamp() {return System.currentTimeMillis();} public IdWorker(long workerId, long datacenterId, long sequence) { // 檢查機房id和機器id是否超過31 不能小于0if (workerId > maxWorkerId || workerId < 0) {throw new IllegalArgumentException(String.format('worker Id can’t be greater than %d or less than 0',maxWorkerId));} if (datacenterId > maxDatacenterId || datacenterId < 0) { throw new IllegalArgumentException(String.format('datacenter Id can’t be greater than %d or less than 0',maxDatacenterId));}this.workerId = workerId;this.datacenterId = datacenterId;this.sequence = sequence;} // 這個是核心方法,通過調用nextId()方法,讓當前這臺機器上的snowflake算法程序生成一個全局唯一的idpublic synchronized long nextId() {// 這兒就是獲取當前時間戳,單位是毫秒long timestamp = timeGen();if (timestamp < lastTimestamp) { System.err.printf('clock is moving backwards. Rejecting requests until %d.', lastTimestamp);throw new RuntimeException(String.format('Clock moved backwards. Refusing to generate id for %d milliseconds',lastTimestamp - timestamp));} // 下面是說假設在同一個毫秒內,又發送了一個請求生成一個id// 這個時候就得把seqence序號給遞增1,最多就是4096if (lastTimestamp == timestamp) { // 這個意思是說一個毫秒內最多只能有4096個數字,無論你傳遞多少進來,//這個位運算保證始終就是在4096這個范圍內,避免你自己傳遞個sequence超過了4096這個范圍sequence = (sequence + 1) & sequenceMask;//當某一毫秒的時間,產生的id數 超過4095,系統會進入等待,直到下一毫秒,系統繼續產生IDif (sequence == 0) {timestamp = tilNextMillis(lastTimestamp);} } else {sequence = 0;}// 這兒記錄一下最近一次生成id的時間戳,單位是毫秒lastTimestamp = timestamp;// 這兒就是最核心的二進制位運算操作,生成一個64bit的id// 先將當前時間戳左移,放到41 bit那兒;將機房id左移放到5 bit那兒;將機器id左移放到5 bit那兒;將序號放最后12 bit// 最后拼接起來成一個64 bit的二進制數字,轉換成10進制就是個long型return ((timestamp - twepoch) << timestampLeftShift) |(datacenterId << datacenterIdShift) |(workerId << workerIdShift) | sequence;} /** * 當某一毫秒的時間,產生的id數 超過4095,系統會進入等待,直到下一毫秒,系統繼續產生ID * @param lastTimestamp * @return */private long tilNextMillis(long lastTimestamp) { long timestamp = timeGen(); while (timestamp <= lastTimestamp) {timestamp = timeGen();}return timestamp;}//獲取當前時間戳private long timeGen(){return System.currentTimeMillis();} /** * main 測試類 * @param args */public static void main(String[] args) {System.out.println(1&4596);System.out.println(2&4596);System.out.println(6&4596);System.out.println(6&4596);System.out.println(6&4596);System.out.println(6&4596);//IdWorker worker = new IdWorker(1,1,1);//for (int i = 0; i < 22; i++) {//System.out.println(worker.nextId());//}}}
SnowFlake算法的優點:
(1)高性能高可用:生成時不依賴于數據庫,完全在內存中生成。
(2)容量大:每秒中能生成數百萬的自增ID。
(3)ID自增:存入數據庫中,索引效率高。
SnowFlake算法的缺點:
依賴與系統時間的一致性,如果系統時間被回調,或者改變,可能會造成id沖突或者重復。
實際中我們的機房并沒有那么多,我們可以改進改算法,將10bit的機器id優化,成業務表或者和我們系統相關的業務。
到此這篇關于Java實現雪花算法的原理的文章就介紹到這了,更多相關Java 雪花算法內容請搜索好吧啦網以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持好吧啦網!
相關文章:
 網公網安備
網公網安備