使用python 計算百分位數實現數據分箱代碼
對于百分位數,相信大家都比較熟悉,以下解釋源引自百度百科。
百分位數,如果將一組數據從小到大排序,并計算相應的累計百分位,則某一百分位所對應數據的值就稱為這一百分位的百分位數。可表示為:一組n個觀測值按數值大小排列。如,處于p%位置的值稱第p百分位數。
因為百分位數是采用等分的方式劃分數據,因此也可用此方法進行等頻分箱。
import pandas as pdimport numpy as npimport randomt=pd.DataFrame(columns=[’l’,’s’])#隨機生成1000個0到999整數t[’l’]=[random.randint(0,999) for _range in range(1000)]#定義s為1,便于統計t[’s’]=1#通過np.percentile找到分位點l_bin=[]for i in range(0,101,10): l_bin.append(np.percentile(t[’l’],i))#分位點最后一個數加上一個極小的數,否則切分后數字999會標記為nanl_bin[-1]+=1/1e10print(’分位點:’,np.array(l_bin).round(2))#對隨機數進行切分,right=False時左閉右開t[’box’]=pd.cut(t[’l’],l_bin,right=False)tj=t.groupby(’box’)[’s’].agg(’sum’)print(’分箱統計’)print(tj)#生成新的標簽label=[]for i in range(len(l_bin)-1): label.append(str(l_bin[i].round(4))+’+’)#原標簽和自定義的新標簽生成字典 list_box_td=list(set(t[’box’]))list_box_td.sort()dict_t=dict(zip(list_box_td,label))#根據字典進行替換t[’new_box’]=t[’box’].replace(dict_t)print(’新分箱統計’)tj=t.groupby(’new_box’)[’s’].agg(’sum’)print(tj)del t[’s’]print(t.head())
輸出結果:
分位點: [ 0. 90.9 194.6 290. 386. 473.5 589. 688. 783.2 884.2 997. ]分箱統計box[0.0, 90.9) 100[90.9, 194.6) 100[194.6, 290.0) 99[290.0, 386.0) 99[386.0, 473.5) 102[473.5, 589.0) 99[589.0, 688.0) 100[688.0, 783.2) 101[783.2, 884.2) 100[884.2, 997.0) 100Name: s, dtype: int64新分箱統計new_box0.0+ 100194.6+ 99290.0+ 99386.0+ 102473.5+ 99589.0+ 100688.0+ 101783.2+ 100884.2+ 10090.9+ 100Name: s, dtype: int64 l box new_box0 253 [194.6, 290.0) 194.6+1 468 [386.0, 473.5) 386.0+2 130 [90.9, 194.6) 90.9+3 476 [473.5, 589.0) 473.5+4 656 [589.0, 688.0) 589.0+
可以看出每個分箱內,約有100個數字。根據這個方法,可以自定義一些標簽。
補充拓展:python 計算動態時點的百分位數
【說明】
1、動態時點:每次計算的數據框為截止于當前行的數據,即累計行(多次計算);
2、靜態時點(當前時間):計算的數據框為所有行(一次計算);
【代碼】
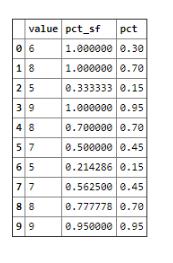
test = pd.DataFrame(np.random.randint(1, 10, size=10), columns=[’value’]) # 生成[1,10]的隨機整數test[’pct_sf’] = test.index.map(lambda x: test.ix[:x].value.rank(pct=True)[x]) # 動態時點test[’pct’] = test.value.rank(pct=True) # 當前時點test
以上這篇使用python 計算百分位數實現數據分箱代碼就是小編分享給大家的全部內容了,希望能給大家一個參考,也希望大家多多支持好吧啦網。
相關文章:

 網公網安備
網公網安備