Python讀取VOC中的xml目標(biāo)框?qū)嵗?/h1>
瀏覽:4日期:2022-08-03 08:34:03
代碼:
#!/usr/bin/python# -*- coding: UTF-8 -*-# get annotation object bndbox locationimport osimport cv2try: import xml.etree.cElementTree as ET #解析xml的c語(yǔ)言版的模塊except ImportError: import xml.etree.ElementTree as ET ##get object annotation bndbox loc start def GetAnnotBoxLoc(AnotPath):#AnotPath VOC標(biāo)注文件路徑 tree = ET.ElementTree(file=AnotPath) #打開文件,解析成一棵樹型結(jié)構(gòu) root = tree.getroot()#獲取樹型結(jié)構(gòu)的根 ObjectSet=root.findall(’object’)#找到文件中所有含有object關(guān)鍵字的地方,這些地方含有標(biāo)注目標(biāo) ObjBndBoxSet={} #以目標(biāo)類別為關(guān)鍵字,目標(biāo)框?yàn)橹到M成的字典結(jié)構(gòu) for Object in ObjectSet: ObjName=Object.find(’name’).text BndBox=Object.find(’bndbox’) x1 = int(BndBox.find(’xmin’).text)#-1 #-1是因?yàn)槌绦蚴前?作為起始位置的 y1 = int(BndBox.find(’ymin’).text)#-1 x2 = int(BndBox.find(’xmax’).text)#-1 y2 = int(BndBox.find(’ymax’).text)#-1 BndBoxLoc=[x1,y1,x2,y2] if ObjName in ObjBndBoxSet: ObjBndBoxSet[ObjName].append(BndBoxLoc)#如果字典結(jié)構(gòu)中含有這個(gè)類別了,那么這個(gè)目標(biāo)框要追加到其值的末尾 else: ObjBndBoxSet[ObjName]=[BndBoxLoc]#如果字典結(jié)構(gòu)中沒有這個(gè)類別,那么這個(gè)目標(biāo)框就直接賦值給其值吧 return ObjBndBoxSet##get object annotation bndbox loc enddef display(objBox,pic): img = cv2.imread(pic) for key in objBox.keys(): for i in range(len(objBox[key])): cv2.rectangle(img, (objBox[key][i][0],objBox[key][i][1]), (objBox[key][i][2], objBox[key][i][3]), (0, 0, 255), 2) cv2.putText(img, key, (objBox[key][i][0],objBox[key][i][1]), cv2.FONT_HERSHEY_COMPLEX, 1, (255,0,0), 1) cv2.imshow(’img’,img) cv2.imwrite(’display.jpg’,img) cv2.waitKey(0)if __name__== ’__main__’: pic = r'./VOCdevkit/VOC2007/JPEGImages/000282.jpg' ObjBndBoxSet=GetAnnotBoxLoc(r'./VOCdevkit/VOC2007/Annotations/000282.xml') print(ObjBndBoxSet) display(ObjBndBoxSet,pic)
輸出結(jié)果:
{’chair’: [[335, 263, 484, 373]], ’person’: [[327, 104, 476, 300], [232, 57, 357, 374], [3, 32, 199, 374], [58, 139, 296, 374]]}
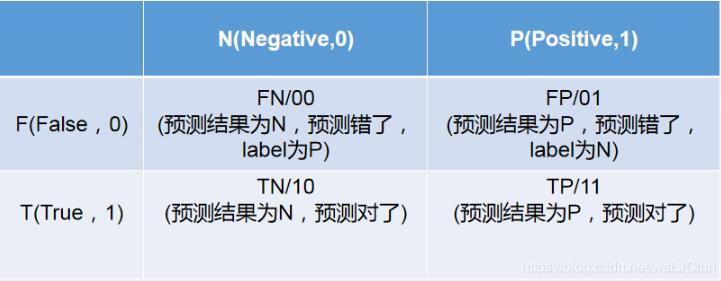
圖示:
![Python讀取VOC中的xml目標(biāo)框?qū)嵗? src=]()
補(bǔ)充知識(shí):使用python將voc類型標(biāo)注xml文件對(duì)圖片進(jìn)行目標(biāo)還原,以及批量裁剪特定類
使用標(biāo)注工具如labelimg對(duì)圖片物體進(jìn)行voc類型標(biāo)注,會(huì)生成xml文件,如何判斷別人的數(shù)據(jù)集做的好不好,可以用以下代碼進(jìn)行目標(biāo)還原。
import xml.etree.cElementTree as ETimport cv2import osimport globdef GetAnnotBoxLoc(AnotPath): tree = ET.ElementTree(file=AnotPath) root = tree.getroot() ObjectSet=root.findall(’object’) ObjBndBoxSet={} for Object in ObjectSet: ObjName=Object.find(’name’).text BndBox=Object.find(’bndbox’) x1 = int(BndBox.find(’xmin’).text) y1 = int(BndBox.find(’ymin’).text) x2 = int(BndBox.find(’xmax’).text) y2 = int(BndBox.find(’ymax’).text) BndBoxLoc=[x1,y1,x2,y2] if ObjName in ObjBndBoxSet: ObjBndBoxSet[ObjName].append(BndBoxLoc) else: ObjBndBoxSet[ObjName]=[BndBoxLoc] return ObjBndBoxSetdef GetAnnotName(AnotPath): tree = ET.ElementTree(file=AnotPath) root = tree.getroot() path=root.find(’path’).text return pathdef Drawpic(xml_path,result_path): n = 0 xmls = glob.glob(os.path.join(xml_path, ’*.xml’)) for xml in xmls: n = n + 1 box=GetAnnotBoxLoc(xml) path=GetAnnotName(xml) img = cv2.imread(path) for classes in list(box.keys()): for boxes in box[classes]:if classes == 'bad1': cv2.rectangle(img,(int(boxes[0]),int(boxes[1])),(int(boxes[2]),int(boxes[3])),(255,0,0),3) #blueif classes == 'bad2': cv2.rectangle(img,(int(boxes[0]),int(boxes[1])),(int(boxes[2]),int(boxes[3])),(0,255,0),3) #greenif classes == 'bad3': cv2.rectangle(img,(int(boxes[0]),int(boxes[1])),(int(boxes[2]),int(boxes[3])),(0,0,255),3) #red cv2.imwrite(result_path+'/'+str(n)+'_result.jpg', img) print(path,'還原成功')Drawpic('/home/wxy/Dashboard/dataset/VOCdevkit/VOC2012/Annotations','/home/wxy/Dashboard/dataset/VOCdevkit/VOC2012/test')
使用labelimg對(duì)圖像進(jìn)行標(biāo)注,folder目錄需要修改一下
import xml.etree.ElementTree as ETimport osfor i in os.listdir(’/home/wxy/Dashboard/dataset/VOCdevkit/VOC2012/Annotations’): tree = ET.parse(’/home/wxy/Dashboard/dataset/VOCdevkit/VOC2012/Annotations’+’/’+i) root = tree.getroot() print(root.find(’folder’).text) root.find(’folder’).text = ’VOC2012’ print(root.find(’folder’).text) tree.write(’/home/wxy/Dashboard/dataset/VOCdevkit/VOC2012/Annotations’+’/’+i)
批量裁剪特定類,xml.dom.minidom好像比xml.etree.cElementTree好用啊。
#coding=utf-8import xml.dom.minidomimport cv2import osfor name in os.listdir('./Annotations/'): dom=xml.dom.minidom.parse('./Annotations/'+name) root=dom.documentElement object_name=root.getElementsByTagName(’name’) if(object_name[0].firstChild.data == 'normal'): print(name) xmin=root.getElementsByTagName(’xmin’) ymin=root.getElementsByTagName(’ymin’) xmax=root.getElementsByTagName(’xmax’) ymax=root.getElementsByTagName(’ymax’) x_min = int(xmin[0].firstChild.data) y_min = int(ymin[0].firstChild.data) x_max = int(xmax[0].firstChild.data) y_max = int(ymax[0].firstChild.data) img=cv2.imread('./JPEGImages/'+name[:-4]+'.jpg') cropped=img[y_min:y_max,x_min:x_max] cv2.imwrite('./cut_jpg/'+name[:-4]+'.jpg', cropped)
以上這篇Python讀取VOC中的xml目標(biāo)框?qū)嵗褪切【幏窒斫o大家的全部?jī)?nèi)容了,希望能給大家一個(gè)參考,也希望大家多多支持好吧啦網(wǎng)。
相關(guān)文章:
1. python 如何在 Matplotlib 中繪制垂直線2. bootstrap select2 動(dòng)態(tài)從后臺(tái)Ajax動(dòng)態(tài)獲取數(shù)據(jù)的代碼3. ASP常用日期格式化函數(shù) FormatDate()4. python中@contextmanager實(shí)例用法5. html中的form不提交(排除)某些input 原創(chuàng)6. CSS3中Transition屬性詳解以及示例分享7. js select支持手動(dòng)輸入功能實(shí)現(xiàn)代碼8. 如何通過python實(shí)現(xiàn)IOU計(jì)算代碼實(shí)例9. 開發(fā)效率翻倍的Web API使用技巧10. vue使用moment如何將時(shí)間戳轉(zhuǎn)為標(biāo)準(zhǔn)日期時(shí)間格式
代碼:
#!/usr/bin/python# -*- coding: UTF-8 -*-# get annotation object bndbox locationimport osimport cv2try: import xml.etree.cElementTree as ET #解析xml的c語(yǔ)言版的模塊except ImportError: import xml.etree.ElementTree as ET ##get object annotation bndbox loc start def GetAnnotBoxLoc(AnotPath):#AnotPath VOC標(biāo)注文件路徑 tree = ET.ElementTree(file=AnotPath) #打開文件,解析成一棵樹型結(jié)構(gòu) root = tree.getroot()#獲取樹型結(jié)構(gòu)的根 ObjectSet=root.findall(’object’)#找到文件中所有含有object關(guān)鍵字的地方,這些地方含有標(biāo)注目標(biāo) ObjBndBoxSet={} #以目標(biāo)類別為關(guān)鍵字,目標(biāo)框?yàn)橹到M成的字典結(jié)構(gòu) for Object in ObjectSet: ObjName=Object.find(’name’).text BndBox=Object.find(’bndbox’) x1 = int(BndBox.find(’xmin’).text)#-1 #-1是因?yàn)槌绦蚴前?作為起始位置的 y1 = int(BndBox.find(’ymin’).text)#-1 x2 = int(BndBox.find(’xmax’).text)#-1 y2 = int(BndBox.find(’ymax’).text)#-1 BndBoxLoc=[x1,y1,x2,y2] if ObjName in ObjBndBoxSet: ObjBndBoxSet[ObjName].append(BndBoxLoc)#如果字典結(jié)構(gòu)中含有這個(gè)類別了,那么這個(gè)目標(biāo)框要追加到其值的末尾 else: ObjBndBoxSet[ObjName]=[BndBoxLoc]#如果字典結(jié)構(gòu)中沒有這個(gè)類別,那么這個(gè)目標(biāo)框就直接賦值給其值吧 return ObjBndBoxSet##get object annotation bndbox loc enddef display(objBox,pic): img = cv2.imread(pic) for key in objBox.keys(): for i in range(len(objBox[key])): cv2.rectangle(img, (objBox[key][i][0],objBox[key][i][1]), (objBox[key][i][2], objBox[key][i][3]), (0, 0, 255), 2) cv2.putText(img, key, (objBox[key][i][0],objBox[key][i][1]), cv2.FONT_HERSHEY_COMPLEX, 1, (255,0,0), 1) cv2.imshow(’img’,img) cv2.imwrite(’display.jpg’,img) cv2.waitKey(0)if __name__== ’__main__’: pic = r'./VOCdevkit/VOC2007/JPEGImages/000282.jpg' ObjBndBoxSet=GetAnnotBoxLoc(r'./VOCdevkit/VOC2007/Annotations/000282.xml') print(ObjBndBoxSet) display(ObjBndBoxSet,pic)
輸出結(jié)果:
{’chair’: [[335, 263, 484, 373]], ’person’: [[327, 104, 476, 300], [232, 57, 357, 374], [3, 32, 199, 374], [58, 139, 296, 374]]}
圖示:
補(bǔ)充知識(shí):使用python將voc類型標(biāo)注xml文件對(duì)圖片進(jìn)行目標(biāo)還原,以及批量裁剪特定類
使用標(biāo)注工具如labelimg對(duì)圖片物體進(jìn)行voc類型標(biāo)注,會(huì)生成xml文件,如何判斷別人的數(shù)據(jù)集做的好不好,可以用以下代碼進(jìn)行目標(biāo)還原。
import xml.etree.cElementTree as ETimport cv2import osimport globdef GetAnnotBoxLoc(AnotPath): tree = ET.ElementTree(file=AnotPath) root = tree.getroot() ObjectSet=root.findall(’object’) ObjBndBoxSet={} for Object in ObjectSet: ObjName=Object.find(’name’).text BndBox=Object.find(’bndbox’) x1 = int(BndBox.find(’xmin’).text) y1 = int(BndBox.find(’ymin’).text) x2 = int(BndBox.find(’xmax’).text) y2 = int(BndBox.find(’ymax’).text) BndBoxLoc=[x1,y1,x2,y2] if ObjName in ObjBndBoxSet: ObjBndBoxSet[ObjName].append(BndBoxLoc) else: ObjBndBoxSet[ObjName]=[BndBoxLoc] return ObjBndBoxSetdef GetAnnotName(AnotPath): tree = ET.ElementTree(file=AnotPath) root = tree.getroot() path=root.find(’path’).text return pathdef Drawpic(xml_path,result_path): n = 0 xmls = glob.glob(os.path.join(xml_path, ’*.xml’)) for xml in xmls: n = n + 1 box=GetAnnotBoxLoc(xml) path=GetAnnotName(xml) img = cv2.imread(path) for classes in list(box.keys()): for boxes in box[classes]:if classes == 'bad1': cv2.rectangle(img,(int(boxes[0]),int(boxes[1])),(int(boxes[2]),int(boxes[3])),(255,0,0),3) #blueif classes == 'bad2': cv2.rectangle(img,(int(boxes[0]),int(boxes[1])),(int(boxes[2]),int(boxes[3])),(0,255,0),3) #greenif classes == 'bad3': cv2.rectangle(img,(int(boxes[0]),int(boxes[1])),(int(boxes[2]),int(boxes[3])),(0,0,255),3) #red cv2.imwrite(result_path+'/'+str(n)+'_result.jpg', img) print(path,'還原成功')Drawpic('/home/wxy/Dashboard/dataset/VOCdevkit/VOC2012/Annotations','/home/wxy/Dashboard/dataset/VOCdevkit/VOC2012/test')
使用labelimg對(duì)圖像進(jìn)行標(biāo)注,folder目錄需要修改一下
import xml.etree.ElementTree as ETimport osfor i in os.listdir(’/home/wxy/Dashboard/dataset/VOCdevkit/VOC2012/Annotations’): tree = ET.parse(’/home/wxy/Dashboard/dataset/VOCdevkit/VOC2012/Annotations’+’/’+i) root = tree.getroot() print(root.find(’folder’).text) root.find(’folder’).text = ’VOC2012’ print(root.find(’folder’).text) tree.write(’/home/wxy/Dashboard/dataset/VOCdevkit/VOC2012/Annotations’+’/’+i)
批量裁剪特定類,xml.dom.minidom好像比xml.etree.cElementTree好用啊。
#coding=utf-8import xml.dom.minidomimport cv2import osfor name in os.listdir('./Annotations/'): dom=xml.dom.minidom.parse('./Annotations/'+name) root=dom.documentElement object_name=root.getElementsByTagName(’name’) if(object_name[0].firstChild.data == 'normal'): print(name) xmin=root.getElementsByTagName(’xmin’) ymin=root.getElementsByTagName(’ymin’) xmax=root.getElementsByTagName(’xmax’) ymax=root.getElementsByTagName(’ymax’) x_min = int(xmin[0].firstChild.data) y_min = int(ymin[0].firstChild.data) x_max = int(xmax[0].firstChild.data) y_max = int(ymax[0].firstChild.data) img=cv2.imread('./JPEGImages/'+name[:-4]+'.jpg') cropped=img[y_min:y_max,x_min:x_max] cv2.imwrite('./cut_jpg/'+name[:-4]+'.jpg', cropped)
以上這篇Python讀取VOC中的xml目標(biāo)框?qū)嵗褪切【幏窒斫o大家的全部?jī)?nèi)容了,希望能給大家一個(gè)參考,也希望大家多多支持好吧啦網(wǎng)。
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備