Python多線程Threading、子線程與守護線程實例詳解
本文實例講述了Python多線程Threading、子線程與守護線程。分享給大家供大家參考,具體如下:
線程與進程: 線程對于進程來說,就好似工廠里的工人,分配資源是分配到工廠,工人再去處理。 線程是被系統獨立調度和分派的基本單位,線程自己不擁有系統資源,只擁有一點兒在運行中必不可少的資源,但它可與同屬一個進程的其它線程共享進程所擁有的全部資源。 在單個程序中同時運行多個線程完成不同的工作,稱為多線程 對于IO密集型的程序來說,多線程可以利用讀IO的時間去做其他事【IO并不占用CPU,這就好像A買個一份外賣,他只需要等著送過來然后敲A家的門就行了】; 而對于CPU密集型的程序來說,多線程的效率就不是很高了【CPU由于要計算,切換之間要恢復之前的現場消耗相對較大,比如我同時做幾份作業,一份作業做十分鐘,假如十分鐘做不完一份作業,那么我后面再回頭做的時候,我就要好好想想剛才做到哪,剛才想到哪】補充:IO需要CPU嗎?知乎:https://www.zhihu.com/question/27734728

python中多線程需要使用threading模塊
線程的創建與運行:1.直接調用threading的Thread類:
線程的創建:線程對象=thread.Thread(target=函數名,args=(參數))【補充,由于args是一個元組,單個參數時要加“,”】
線程的啟動:線程對象.start(),調用start(),那么線程對象會自動去調用thread.Thread中的run()
讓主線程等待其余線程結束:線程對象.join(),加了join之后,相當于阻塞了主線程,主線程只有當join的線程結束后才會向下執行
import threading,timedef run(n): time.sleep(1) print('task ',n)t1=threading.Thread(target=run,args=('t1',))t2 = threading.Thread(target=run,args=('t2',))start_time=time.time()#開始時間t1.start()t2.start()##因為是獨立線程,如果想要主線程等待其他線程運行完畢,需要使用joint1.join()t2.join()spend_time=time.time()-start_timeprint(spend_time)##1.0多,說明是并行的結果
附加說明--join是阻塞等待:
import threading,timeclass MyTread(threading.Thread): def __init__(self,name): super(MyTread,self).__init__()#調用父類的__init__() self.name=name def run(self):#重寫方法,按自己的要求去寫 time.sleep(1) print('run in task',self.name,threading.current_thread(),threading.active_count())t1=MyTread('t1')t2=MyTread('t2')start_time=time.time()t1.start()t2.start()t1.join()t2.join()time.sleep(1)###主線程等待其余線程結束print(time.time()-start_time)#結果是2.0多,證明是join是相當于阻塞了主線程的執行,只有當線程結束后才會向下執行
2.繼承threading的Thread類:
繼承threading的Thread類的類要主要做兩件事:
1.如果不做自定義變量的初始化,那么可以直接使用繼承的父類的__init__(),如果需要做自定義變量的初始化,則需要先調用父類的__init__()【否則需要自己填寫線程初始化相關的參數】
2.重寫run,雖然繼承了父類的run,但實際上如果不重寫,那么我們繼承threading的Thread類又有什么意義呢?為什么不直接調用threading的Thread類
import threading,timeclass MyTread(threading.Thread): def __init__(self,name): super(MyTread,self).__init__()#調用父類的__init__() self.name=name def run(self):#重寫方法,按自己的要求去寫 time.sleep(1) print('run in task',self.name,threading.current_thread(),threading.active_count())t1=MyTread('t1')t2=MyTread('t2')start_time=time.time()t1.start()t2.start()###主線程等待其余線程結束t1.join()t2.join()print(time.time()-start_time)#結果是1.0多,證明是并行的 子線程: 由一個線程啟動的線程可以成為它的子線程,A啟動B,B是A的子線程,A是B的父線程 線程的幾個常用函數: threading.current_thread():
返回當前正在運行的線程對象
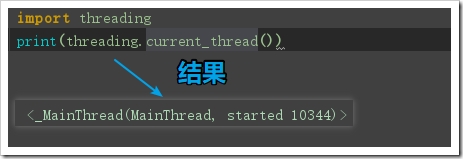 threading.active_count():
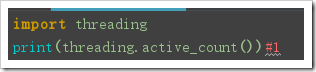
threading.active_count():
返回當前進程中的存活的線程對象數

get_ident():獲取當前線程ID。
守護線程: 守護線程是起到輔助功能的,就好像魔法師放禁咒總要騎士保護一樣【魔法師只需要關系自己的任務,保護他的任務交給守護者】 而守護線程與主線程的關系呢,就好像備胎跟女神,去買東西的話,備胎要一直在外面等女神【守護線程運行結束就狗帶,但不影響主進程結束,由主線程決定運行時間】,女神不需要等待備胎【主線程結束,守護線程也要結束,不管自身任務是否完成】 與join的區別:join是阻塞等待,守護線程是并行的等待 設置守護線程:線程對象.setDaemon(True)【注意!!!!!設置守護線程必須要在start()前面,不然會報錯】下面的代碼顯示了主線程并不會等待其守護線程結束:
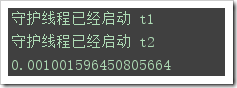
import threading,timeclass MyTread(threading.Thread): def __init__(self,name): super(MyTread,self).__init__() self.name=name def run(self): print('守護線程已經啟動',self.name) time.sleep(1) print('run in task',self.name,threading.current_thread(),threading.active_count())t1=MyTread('t1')t1.setDaemon(True)t2=MyTread('t2')t2.setDaemon(True)start_time=time.time()#開始時間t1.start()t2.start()spend_time=time.time()-start_timeprint(spend_time)##0.0多,而且三個線程都執行完畢了,說明這個是并行的等待
讓主線程sleep一下,顯示一下如果主線程要等待守護線程,那么是并行的等待:
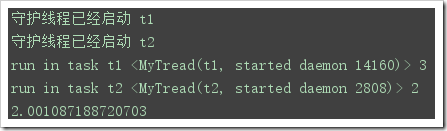
import threading,timeclass MyTread(threading.Thread): def __init__(self,name): super(MyTread,self).__init__() self.name=name def run(self): print('守護線程已經啟動',self.name) time.sleep(1) print('run in task',self.name,threading.current_thread(),threading.active_count())t1=MyTread('t1')t1.setDaemon(True)t2=MyTread('t2')t2.setDaemon(True)start_time=time.time()#開始時間t1.start()t2.start()time.sleep(2)spend_time=time.time()-start_timeprint(spend_time)##2.0多,而且三個線程都執行完畢了,說明這個是并行的等待
更多關于Python相關內容感興趣的讀者可查看本站專題:《Python進程與線程操作技巧總結》、《Python數據結構與算法教程》、《Python函數使用技巧總結》、《Python字符串操作技巧匯總》、《Python入門與進階經典教程》、《Python+MySQL數據庫程序設計入門教程》及《Python常見數據庫操作技巧匯總》
希望本文所述對大家Python程序設計有所幫助。
相關文章:

 網公網安備
網公網安備