python爬蟲學習筆記之pyquery模塊基本用法詳解
本文實例講述了python爬蟲學習筆記之pyquery模塊基本用法。分享給大家供大家參考,具體如下:
相關內容: pyquery的介紹 pyquery的使用 安裝模塊 導入模塊 解析對象初始化 css選擇器 在選定元素之后的元素再選取 元素的文本、屬性等內容的獲取 pyquery執行DOM操作、css操作 Dom操作 CSS操作 一個利用pyquery爬取豆瓣新書的例子首發時間:2018-03-09 21:26
pyquery的介紹 pyquery允許對xml、html文檔進行jQuery查詢。 pyquery使用lxml進行快速xml和html操作。 pyquery是python中的jqueryPyQuery的使用:1.安裝模塊:pip3 install pyquery2.導入模塊:
from pyquery import PyQuery as pq3.解析對象初始化:
【使用PyQuery初始化解析對象,PyQuery是一個類,直接將要解析的對象作為參數傳入即可】
解析對象為字符串時字符串初始化 :默認情況下是字符串,如果字符串是一個帶httphttps前綴的,將會認為是一個urltextParse = pq(html) 解析對象為網頁時url初始化: 建議使用關鍵字參數url=
# urlParse = pq(’http://www.baidu.com’) #1urlParse = pq(url=’http://www.baidu.com’) #2 解析對象為文件時文件初始化:建議使用關鍵字參數filename=
fileParse = pq(filename='L:demo.html') 解析完畢后,就可以使用相關函數或變量來進行篩選,可以使用css等來篩選,4.CSS選擇器: 利用標簽獲取:
result = textParse(’h2’).text() 利用類選擇器:
result3=textParse('.p1').text() 利用id選擇:
result4=textParse('#user').attr('type') 分組選擇:
result5=textParse('p,div').text() 后代選擇器:
result6=textParse('div a').attr.href 屬性選擇器:
result7=textParse('[class=’p1’]').text() CSS3偽類選擇器:
result8=textParse('p:last').text()
(更多的,可以參考css)
5.在選定元素之后的元素再選取: find():找出指定子元素 ,find可以有參數,該參數可以是任何 jQuery 選擇器的語法, filter():對結果進行過濾,找出指定元素 ,filter可以有參數,該參數可以是任何 jQuery 選擇器的語法, children():獲取所有子元素,可以有參數,該參數可以是任何 jQuery 選擇器的語法, parent():獲取父元素,可以有參數,該參數可以是任何 jQuery 選擇器的語法, parents():獲取祖先元素,可以有參數,該參數可以是任何 jQuery 選擇器的語法, siblings():獲取兄弟元素,可以有參數,該參數可以是任何 jQuery 選擇器的語法,from pyquery import PyQuery as pqhtml='''<html><head></head><body><h2>This is a heading</h2><p class='p1'>This is a paragraph.</p><p class='p2'>This is another paragraph.</p><div> 123<a rel='external nofollow' rel='external nofollow' rel='external nofollow' >hello</a></div><input type='Button' ><input type='text' ></body>'''###初始化textParse = pq(html)# urlParse = pq(’http://www.baidu.com’) #1# urlParse = pq(url=’http://www.baidu.com’) #2# fileParse = pq(filename='L:demo.html')##獲取result = textParse(’h2’).text()print(result)result2= textParse(’div’).html()print(result2)result3=textParse('.p1').text()print(result3)result4=textParse('#user').attr('type')print(result4)result5=textParse('p,div').text()print(result5)result6=textParse('div a').attr.hrefprint(result6)result7=textParse('[class=’p1’]').text()print(result7)result8=textParse('p:last').text()print(result8)result9=textParse('div').find('a').text()print(result9)result12=textParse('p').filter('.p1').text()print(result12)result10=textParse('div').children()print(result10)result11=textParse('a').parent()print(result11)6.元素的文本、屬性等內容的獲取:
attr(attribute):獲取屬性
result2=textParse('a').attr('href')
attr.xxxx:獲取屬性xxxx
result21=textParse('a').attr.hrefresult22=textParse('a').attr.class_
text():獲取文本,子元素中也僅僅返回文本
result1=textParse('a').text()
html():獲取html,功能與text類似,但返回html標簽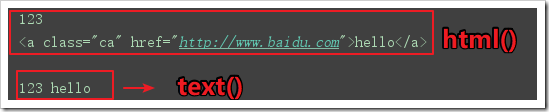
result3=textParse('div').html()
補充1:
元素的迭代:如果返回的結果是多個元素,如果想迭代出每個元素,可以使用items():

補充2:pyquery是jquery的python化,語法基本都是相通的,想了解更多,可以參考jquery。
pyquery執行DOM操作、css操作:DOM操作:add_class():增加class
remove_class():移除class
remove():刪除指定元素
from pyquery import PyQuery as pqhtml='''<html><head></head><body><h2>This is a heading</h2><p class='p1'>This is a paragraph.</p><p class='p2'>This is another paragraph.</p><div style='color:blue'> 123<a rel='external nofollow' rel='external nofollow' rel='external nofollow' >hello</a></div><input type='Button' ><input type='text' ></body>'''textParse=pq(html)textParse(’a’).add_class('c1')print(textParse(’a’).attr('class'))textParse(’a’).remove_class('c1')print(textParse(’a’).attr('class'))print(textParse(’div’).html())textParse(’div’).remove('a')print(textParse(’div’).html())css操作: attr():設置屬性 設置格式:attr('屬性名','屬性值') css():設置css 設置格式1:css('css樣式','樣式值') 格式2:css({'樣式1':'樣式值','樣式2':'樣式值'})
from pyquery import PyQuery as pqhtml='''<html><head></head><body><h2>This is a heading</h2><p class='p1'>This is a paragraph.</p><p class='p2'>This is another paragraph.</p><div style='color:blue'> 123<a rel='external nofollow' rel='external nofollow' rel='external nofollow' >hello</a></div><input type='Button' ><input type='text' ></body>'''textParse=pq(html)textParse(’a’).attr('name','hehe')print(textParse(’a’).attr('name'))textParse(’a’).css('color','white')textParse(’a’).css({'background-color':'black','postion':'fixed'})print(textParse(’a’).attr('style'))
這些操作什么時候會被用到:
【有時候可能會將數據樣式處理一下再存儲下來,就需要用到,比如我獲取下來的數據樣式我不滿意,可以自定義成我自己的格式】
【有時候需要逐層清理再篩選出指定結果,比如<div>123<a></a></div>中,如果僅僅想要獲取123就可以先刪除<a>再獲取】
一個利用pyquery爬取豆瓣新書的例子:先使用審查元素,定位目標元素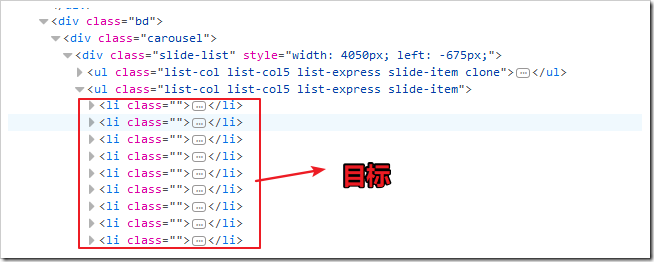
確認爬取信息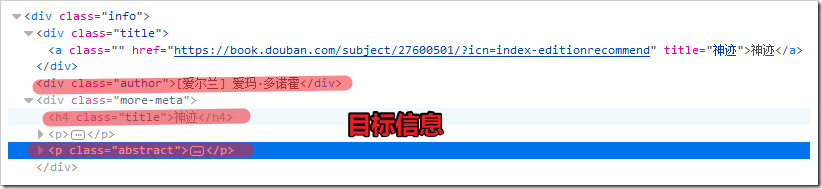
要注意的是,豆瓣新書是有一些分在后面頁的,實際上目標應該是li的上一級ul: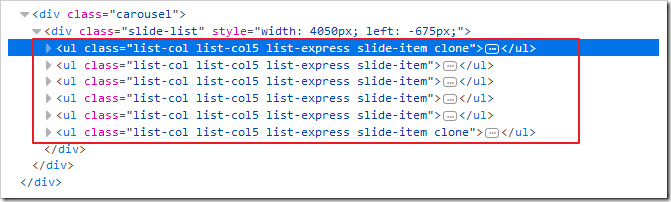
使用PyQuery篩選出結果:
from pyquery import PyQuery as pqurlParse=pq(url='https://book.douban.com/')info=urlParse('div.carousel ul li div.info')file=open('demo.txt','w',encoding='utf8')for i in info.items(): title=i.find('div.title') author=i.find('span.author') abstract=i.find('.abstract') file.write('標題:'+title.text()+'n') file.write('作者:'+author.text()+'n') file.write('概要:'+abstract.text()+'n') file.write('-----------------n') print('n')file.close()
更多關于Python相關內容可查看本站專題:《Python Socket編程技巧總結》、《Python正則表達式用法總結》、《Python數據結構與算法教程》、《Python函數使用技巧總結》、《Python字符串操作技巧匯總》、《Python入門與進階經典教程》及《Python文件與目錄操作技巧匯總》
希望本文所述對大家Python程序設計有所幫助。
相關文章:

 網公網安備
網公網安備