python爬蟲學(xué)習(xí)筆記之Beautifulsoup模塊用法詳解
本文實(shí)例講述了python爬蟲學(xué)習(xí)筆記之Beautifulsoup模塊用法。分享給大家供大家參考,具體如下:
相關(guān)內(nèi)容: 什么是beautifulsoup bs4的使用 導(dǎo)入模塊 選擇使用解析器 使用標(biāo)簽名查找 使用findfind_all查找 使用select查找首發(fā)時間:2018-03-02 00:10
什么是beautifulsoup: 是一個可以從HTML或XML文件中提取數(shù)據(jù)的Python庫.它能夠通過你喜歡的轉(zhuǎn)換器實(shí)現(xiàn)慣用的文檔導(dǎo)航,查找,修改文檔的方式.(官方) beautifulsoup是一個解析器,可以特定的解析出內(nèi)容,省去了我們編寫正則表達(dá)式的麻煩。Beautiful Soup 3 目前已經(jīng)停止開發(fā),我們推薦在現(xiàn)在的項(xiàng)目中使用Beautiful Soup 4
beautifulsoup的版本:最新版是bs4
bs4的使用:1.導(dǎo)入模塊:from bs4 import beautifulsoup2.選擇解析器解析指定內(nèi)容:
soup=beautifulsoup(解析內(nèi)容,解析器)
常用解析器:html.parser,lxml,xml,html5lib
有時候需要安裝安裝解析器:比如pip3 install lxml
BeautifulSoup默認(rèn)支持Python的標(biāo)準(zhǔn)HTML解析庫,但是它也支持一些第三方的解析庫:
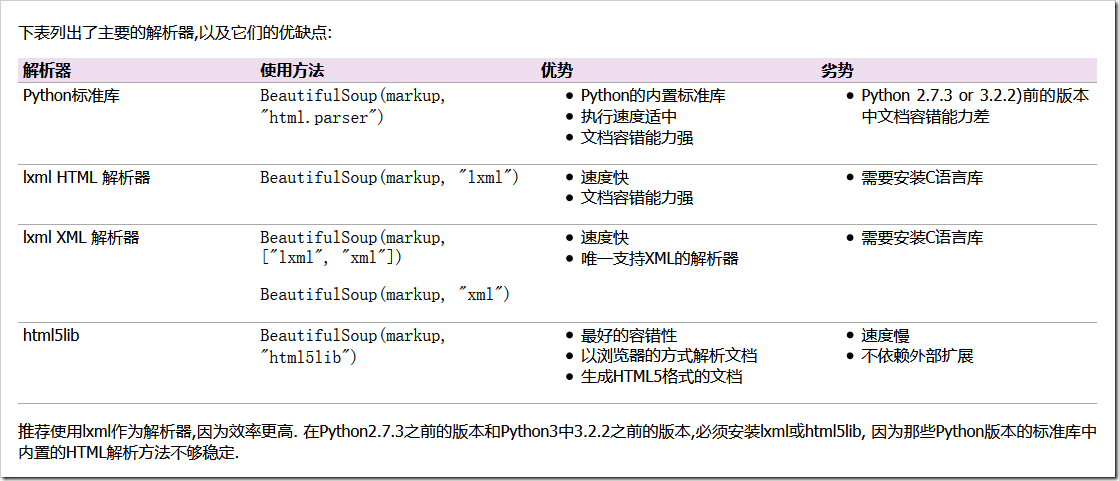
Beautiful Soup為不同的解析器提供了相同的接口,但解析器本身時有區(qū)別的.同一篇文檔被不同的解析器解析后可能會生成不同結(jié)構(gòu)的樹型文檔.區(qū)別最大的是HTML解析器和XML解析器,看下面片段被解析成HTML結(jié)構(gòu):
BeautifulSoup('<a><b /></a>')# <html><head></head><body><a><b></b></a></body></html>
因?yàn)榭諛?biāo)簽<b />不符合HTML標(biāo)準(zhǔn),所以解析器把它解析成<b></b>
同樣的文檔使用XML解析如下(解析XML需要安裝lxml庫).注意,空標(biāo)簽<b />依然被保留,并且文檔前添加了XML頭,而不是被包含在<html>標(biāo)簽內(nèi):
BeautifulSoup('<a><b /></a>', 'xml')# <?xml version='1.0' encoding='utf-8'?># <a><b/></a>
HTML解析器之間也有區(qū)別,如果被解析的HTML文檔是標(biāo)準(zhǔn)格式,那么解析器之間沒有任何差別,只是解析速度不同,結(jié)果都會返回正確的文檔樹.
但是如果被解析文檔不是標(biāo)準(zhǔn)格式,那么不同的解析器返回結(jié)果可能不同.下面例子中,使用lxml解析錯誤格式的文檔,結(jié)果</p>標(biāo)簽被直接忽略掉了:
BeautifulSoup('<a></p>', 'lxml')# <html><body><a></a></body></html>
使用html5lib庫解析相同文檔會得到不同的結(jié)果:
BeautifulSoup('<a></p>', 'html5lib')# <html><head></head><body><a><p></p></a></body></html>
html5lib庫沒有忽略掉</p>標(biāo)簽,而是自動補(bǔ)全了標(biāo)簽,還給文檔樹添加了<head>標(biāo)簽.
使用pyhton內(nèi)置庫解析結(jié)果如下:
BeautifulSoup('<a></p>', 'html.parser')# <a></a>
與lxml [7] 庫類似的,Python內(nèi)置庫忽略掉了</p>標(biāo)簽,與html5lib庫不同的是標(biāo)準(zhǔn)庫沒有嘗試創(chuàng)建符合標(biāo)準(zhǔn)的文檔格式或?qū)⑽臋n片段包含在<body>標(biāo)簽內(nèi),與lxml不同的是標(biāo)準(zhǔn)庫甚至連<html>標(biāo)簽都沒有嘗試去添加.
因?yàn)槲臋n片段“<a></p>”是錯誤格式,所以以上解析方式都能算作”正確”,html5lib庫使用的是HTML5的部分標(biāo)準(zhǔn),所以最接近”正確”.不過所有解析器的結(jié)構(gòu)都能夠被認(rèn)為是”正常”的.
不同的解析器可能影響代碼執(zhí)行結(jié)果,如果在分發(fā)給別人的代碼中使用了 BeautifulSoup ,那么最好注明使用了哪種解析器,以減少不必要的麻煩.
3.操作【約定soup是beautifulsoup(解析內(nèi)容,解析器)返回的解析對象】: 使用標(biāo)簽名查找 使用標(biāo)簽名來獲取結(jié)點(diǎn): soup.標(biāo)簽名 使用標(biāo)簽名來獲取結(jié)點(diǎn)標(biāo)簽名【這個重點(diǎn)是name,主要用于非標(biāo)簽名式篩選時,獲取結(jié)果的標(biāo)簽名】: soup.標(biāo)簽.name 使用標(biāo)簽名來獲取結(jié)點(diǎn)屬性: soup.標(biāo)簽.attrs【獲取全部屬性】 soup.標(biāo)簽.attrs[屬性名]【獲取指定屬性】 soup.標(biāo)簽[屬性名]【獲取指定屬性】 soup.標(biāo)簽.get(屬性名) 使用標(biāo)簽名來獲取結(jié)點(diǎn)的文本內(nèi)容: soup.標(biāo)簽.text soup.標(biāo)簽.string soup.標(biāo)簽.get_text()補(bǔ)充1:上面的篩選方式可以使用嵌套:
print(soup.p.a)#p標(biāo)簽下的a標(biāo)簽
補(bǔ)充2:以上的name,text,string,attrs等方法都可以使用在當(dāng)結(jié)果是一個bs4.element.Tag對象的時候: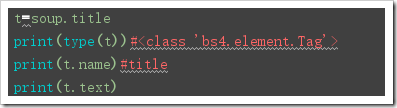
from bs4 import BeautifulSouphtml = '''<html ><head> <meta charset='UTF-8'> <title>this is a title</title></head><body><p class='news'>123</p><p id='i1'>456</p><a rel='external nofollow' rel='external nofollow' rel='external nofollow' rel='external nofollow' rel='external nofollow' >advertisements</a></body></html>'''soup = BeautifulSoup(html,’lxml’)print('獲取結(jié)點(diǎn)'.center(50,’-’))print(soup.head)#獲取head標(biāo)簽print(soup.p)#返回第一個p標(biāo)簽#獲取結(jié)點(diǎn)名print('獲取結(jié)點(diǎn)名'.center(50,’-’))print(soup.head.name)print(soup.find(id=’i1’).name)#獲取文本內(nèi)容print('獲取文本內(nèi)容'.center(50,’-’))print(soup.title.string)#返回title的內(nèi)容print(soup.title.text)#返回title的內(nèi)容print(soup.title.get_text())#獲取屬性print('-----獲取屬性-----')print(soup.p.attrs)#以字典形式返回標(biāo)簽的內(nèi)容print(soup.p.attrs[’class’])#以列表形式返回標(biāo)簽的值print(soup.p[’class’])#以列表形式返回標(biāo)簽的值print(soup.p.get(’class’))#############t=soup.titleprint(type(t))#<class ’bs4.element.Tag’>print(t.name)#titleprint(t.text)#嵌套選擇:print(soup.head.title.string) 獲取子結(jié)點(diǎn)【直接獲取也會獲取到’n’,會認(rèn)為’n’也是一個標(biāo)簽】: soup.標(biāo)簽.contents【返回值是一個列表】 soup.標(biāo)簽.children【返回值是一個可迭代對象,獲取實(shí)際子結(jié)點(diǎn)需要迭代】  獲取子孫結(jié)點(diǎn): soup.標(biāo)簽.descendants【返回值也是一個可迭代對象,實(shí)際子結(jié)點(diǎn)需要迭代】 獲取父結(jié)點(diǎn): soup.標(biāo)簽.parent 獲取祖先結(jié)點(diǎn)[父結(jié)點(diǎn),祖父結(jié)點(diǎn),曾祖父結(jié)點(diǎn)…]: soup.標(biāo)簽.parents【】 獲取兄弟結(jié)點(diǎn): soup.next_sibling【獲取后面的一個兄弟結(jié)點(diǎn)】 soup.next_siblings【獲取后面所有的兄弟結(jié)點(diǎn)】【返回值是一個可迭代對象】 soup.previous_sibling【獲取前一兄弟結(jié)點(diǎn)】 soup.previous_siblings【獲取前面所有的兄弟結(jié)點(diǎn)】【返回值是一個可迭代對象】
獲取子孫結(jié)點(diǎn): soup.標(biāo)簽.descendants【返回值也是一個可迭代對象,實(shí)際子結(jié)點(diǎn)需要迭代】 獲取父結(jié)點(diǎn): soup.標(biāo)簽.parent 獲取祖先結(jié)點(diǎn)[父結(jié)點(diǎn),祖父結(jié)點(diǎn),曾祖父結(jié)點(diǎn)…]: soup.標(biāo)簽.parents【】 獲取兄弟結(jié)點(diǎn): soup.next_sibling【獲取后面的一個兄弟結(jié)點(diǎn)】 soup.next_siblings【獲取后面所有的兄弟結(jié)點(diǎn)】【返回值是一個可迭代對象】 soup.previous_sibling【獲取前一兄弟結(jié)點(diǎn)】 soup.previous_siblings【獲取前面所有的兄弟結(jié)點(diǎn)】【返回值是一個可迭代對象】
補(bǔ)充3:與補(bǔ)充2一樣,上面的函數(shù)都可以使用在當(dāng)結(jié)果是一個bs4.element.Tag對象的時候。
from bs4 import BeautifulSouphtml = '''<html lang='en'><head> <meta charset='UTF-8'> <title>Title</title></head><body><p class='news'><a >123456</a> <a >78910</a></p><p id='i1'></p><a rel='external nofollow' rel='external nofollow' rel='external nofollow' rel='external nofollow' rel='external nofollow' >advertisements</a><span>aspan</span></body></html>'''soup = BeautifulSoup(html, ’lxml’)#獲取子結(jié)點(diǎn)print('獲取子結(jié)點(diǎn)'.center(50,’-’))print(soup.p.contents)print('n')c=soup.p.children#返回的是一個可迭代對象for i,child in enumerate(c): print(i,child)print('獲取子孫結(jié)點(diǎn)'.center(50,’-’))print(soup.p.descendants)c2=soup.p.descendantsfor i,child in enumerate(c2): print(i,child)print('獲取父結(jié)點(diǎn)'.center(50,’-’))c3=soup.title.parentprint(c3)print('獲取父,祖先結(jié)點(diǎn)'.center(50,’-’))c4=soup.title.parentsprint(c4)for i,child in enumerate(c4): print(i,child)print('獲取兄弟結(jié)點(diǎn)'.center(50,’-’))print(soup.p.next_sibling)print(soup.p.previous_sibling)for i,child in enumerate(soup.p.next_siblings): print(i,child,end=’t’)for i,child in enumerate(soup.p.previous_siblings): print(i,child,end=’t’) 使用findfind_all方式: find( name , attrs , recursive , text , **kwargs )【根據(jù)參數(shù)來找出對應(yīng)的標(biāo)簽,但只返回第一個符合條件的結(jié)果】
find_all( name , attrs , recursive , text , **kwargs ):【根據(jù)參數(shù)來找出對應(yīng)的標(biāo)簽,但只返回所有符合條件的結(jié)果】
篩選條件參數(shù)介紹:
name:為標(biāo)簽名,根據(jù)標(biāo)簽名來篩選標(biāo)簽
attrs:為屬性,,根據(jù)屬性鍵值對來篩選標(biāo)簽,賦值方式可以為:屬性名=值,attrs={屬性名:值}【但由于class是python關(guān)鍵字,需要使用class_】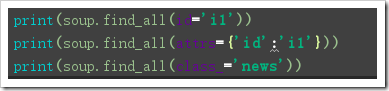
text:為文本內(nèi)容,根據(jù)指定文本內(nèi)容來篩選出標(biāo)簽,【單獨(dú)使用text作為篩選條件,只會返回text,所以一般與其他條件配合使用】
recursive:指定篩選是否遞歸,當(dāng)為False時,不會在子結(jié)點(diǎn)的后代結(jié)點(diǎn)中查找,只會查找子結(jié)點(diǎn)
獲取到結(jié)點(diǎn)后的結(jié)果是一個bs4.element.Tag對象,所以對于獲取屬性、文本內(nèi)容、標(biāo)簽名等操作可以參考前面“使用標(biāo)簽篩選結(jié)果”時涉及的方法
from bs4 import BeautifulSouphtml = '''<html lang='en'><head> <meta charset='UTF-8'> <title>Title</title></head><body><p class='news'><a >123456</a> <a id=’i2’>78910</a></p><p id='i1'></p><a rel='external nofollow' rel='external nofollow' rel='external nofollow' rel='external nofollow' rel='external nofollow' >advertisements</a><span>aspan</span></body></html>'''soup = BeautifulSoup(html, ’lxml’)print('---------------------')print(soup.find_all(’a’),end=’nn’)print(soup.find_all(’a’)[0])print(soup.find_all(attrs={’id’:’i1’}),end=’nn’)print(soup.find_all(class_=’news’),end=’nn’)print(soup.find_all(’a’,text=’123456’))#print(soup.find_all(id=’i2’,recursive=False),end=’nn’)#a=soup.find_all(’a’)print(a[0].name)print(a[0].text)print(a[0].attrs) 使用select篩選【select使用CSS選擇規(guī)則】: soup.select(‘標(biāo)簽名’),代表根據(jù)標(biāo)簽來篩選出指定標(biāo)簽 CSS中#xxx代表篩選id,soup.select(‘#xxx’)代表根據(jù)id篩選出指定標(biāo)簽,返回值是一個列表 CSS中.###代表篩選class,soup.select(’.xxx’)代表根據(jù)class篩選出指定標(biāo)簽,返回值是一個列表 嵌套select: soup.select(“#xxx .xxxx”),如(“#id2 .news”)就是id=”id2”標(biāo)簽下class=”news的標(biāo)簽,返回值是一個列表 獲取到結(jié)點(diǎn)后的結(jié)果是一個bs4.element.Tag對象,所以對于獲取屬性、文本內(nèi)容、標(biāo)簽名等操作可以參考前面“使用標(biāo)簽篩選結(jié)果”時涉及的方法
from bs4 import BeautifulSouphtml = '''<html lang='en'><head> <meta charset='UTF-8'> <title>Title</title></head><body><p class='news'><a >123456</a> <a id=’i2’>78910</a></p><p id='i1'></p><a rel='external nofollow' rel='external nofollow' rel='external nofollow' rel='external nofollow' rel='external nofollow' >advertisements</a><span id=’i4’>aspan</span></body></html>'''soup = BeautifulSoup(html, ’lxml’)sp1=soup.select(’span’)#返回結(jié)果是一個列表,列表的元素是bs4元素標(biāo)簽對象print(soup.select('#i2'),end=’nn’)print(soup.select('.news'),end=’nn’)print(soup.select('.news #i2'),end=’nn’)print(type(sp1),type(sp1[0]))print(sp1[0].name)#列表里面的元素才是bs4元素標(biāo)簽對象print(sp1[0].attrs)print(sp1[0][’class’])
補(bǔ)充4:
對于代碼不齊全的情況下,可以使用soup.prettify()來自動補(bǔ)全,一般情況下建議使用,以避免代碼不齊。
from bs4 import BeautifulSouphtml = '''<html lang='en'><head> <meta charset='UTF-8'> <title>Title</title></head><body><p class='news'><a >123456</a> <a id=’i2’>78910</a></p><p id='i1'></p><a rel='external nofollow' rel='external nofollow' rel='external nofollow' rel='external nofollow' rel='external nofollow' >advertisements</a><span id=’i4’>aspan</html>'''soup = BeautifulSoup(html, ’lxml’)c=soup.prettify()#上述html字符串中末尾缺少</span> 和 </body>print(c)
如果想要獲得更詳細(xì)的介紹,可以參考官方文檔,令人高興的是,有了比較簡易的中文版:
https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html
更多關(guān)于Python相關(guān)內(nèi)容可查看本站專題:《Python Socket編程技巧總結(jié)》、《Python正則表達(dá)式用法總結(jié)》、《Python數(shù)據(jù)結(jié)構(gòu)與算法教程》、《Python函數(shù)使用技巧總結(jié)》、《Python字符串操作技巧匯總》、《Python入門與進(jìn)階經(jīng)典教程》及《Python文件與目錄操作技巧匯總》
希望本文所述對大家Python程序設(shè)計有所幫助。
相關(guān)文章:
1. PHP正則表達(dá)式函數(shù)preg_replace用法實(shí)例分析2. 一個 2 年 Android 開發(fā)者的 18 條忠告3. vue使用moment如何將時間戳轉(zhuǎn)為標(biāo)準(zhǔn)日期時間格式4. js select支持手動輸入功能實(shí)現(xiàn)代碼5. Android 實(shí)現(xiàn)徹底退出自己APP 并殺掉所有相關(guān)的進(jìn)程6. Android studio 解決logcat無過濾工具欄的操作7. 什么是Python變量作用域8. vue-drag-chart 拖動/縮放圖表組件的實(shí)例代碼9. Spring的異常重試框架Spring Retry簡單配置操作10. Vue實(shí)現(xiàn)仿iPhone懸浮球的示例代碼
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備