Python爬蟲抓取論壇關鍵字過程解析
前言:
之前學習了用python爬蟲的基本知識,現在計劃用爬蟲去做一些實際的數據統計功能。由于前段時間演員的誕生帶火了幾個年輕的實力派演員,想用爬蟲程序搜索某論壇中對于某些演員的討論熱度,并按照日期統計每天的討論量。
這個項目總共分為兩步:
1.獲取所有帖子的鏈接:
將最近一個月內的帖子鏈接保存到數組中
2.從回帖中搜索演員名字:
從數組中打開鏈接,翻出該鏈接的所有回帖,在回帖中查找演員的名字
獲取所有帖子的鏈接:
搜索的范圍依然是以虎撲影視區為界限。虎撲影視區一天約5000個回帖,一月下來超過15萬回帖,作為樣本來說也不算小,有一定的參考價值。
完成這一步驟,主要分為以下幾步:
1.獲取當前日期
2.獲取30天前的日期
3.記錄從第一頁往后翻的所有發帖鏈接
1.獲取當前日期
這里我們用到了datetime模塊。使用datetime.datetime.now(),可以獲取當前的日期信息以及時間信息。在這個項目中,只需要用到日期信息就好。
2.獲取30天前的日期
用datetime模塊的優點在于,它還有一個很好用的函數叫做timedelta,可以自行計算時間差。當給定參數days=30時,就會生成30天的時間差,再用當前日期減去delta,可以得到30天前的日期,將該日期保存為startday,即開始進行統計的日期。不然計算時間差需要自行考慮跨年閏年等因素,要通過一個較為復雜的函數才可以完成。
today = datetime.datetime.now()delta = datetime.timedelta(days=30)i = '%s' %(today - delta)startday = i.split(’ ’)[0]today = '%s' %todaytoday = today.split(’ ’)[0]
在獲得開始日期與結束日期后,由于依然需要記錄每一天每個人的討論數,根據這兩個日期生成兩個字典,分別為actor1_dict與actor2_dict。字典以日期為key,以當日討論數目作為value,便于每次新增查找記錄時更新對應的value值。
strptime, strftime = datetime.datetime.strptime, datetime.datetime.strftimedays = (strptime(today, '%Y-%m-%d') - strptime(startday, '%Y-%m-%d')).daysfor i in range(days+1):temp = strftime(strptime(startday, '%Y-%m-%d') + datetime.timedelta(i), '%Y-%m-%d')actor1_dict[temp] = 0actor2_dict[temp] = 0
3.記錄從第一頁往后翻的所有發帖鏈接
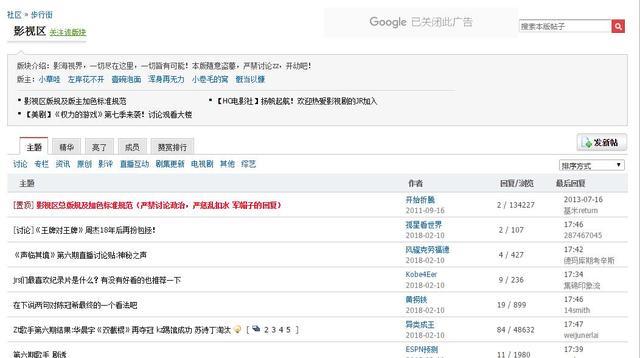

如圖1所示,采用發帖順序排列,可以得到所有的發帖時間(精確到分鐘)。右鍵并點擊查看網頁源代碼,可以發現當前帖子的鏈接頁面,用正則表達式的方式抓取鏈接。
首先依然是獲取30天前的日期,再抓取第i頁的源代碼,用正則表達式去匹配,獲取網頁鏈接和發帖時間。如圖2所示:
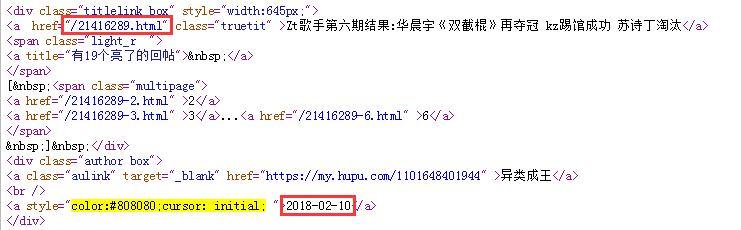
比較發帖時間,如果小于30天前的日期,則獲取發帖鏈接結束,返回當前拿到的鏈接數組,代碼如下
def all_movie_post(ori_url): i = datetime.datetime.now() delta = datetime.timedelta(days=30) i = '%s' %(i - delta) day = i.split(’ ’)[0] # 獲得30天前的日子 print day user_agent = ’Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)’ headers = { ’User-Agent’ : user_agent } post_list = [] for i in range(1,100): request = urllib2.Request(ori_url + ’-{}’.format(i),headers = headers) response = urllib2.urlopen(request) content = response.read().decode(’utf-8’) pattern = re.compile(’<a href='http://www.aoyou183.cn/bcjs/(.*?)' rel='external nofollow' >.*?<a style='color:#808080;cursor: initial; '>(.*?)</a>’, re.S) items = re.findall(pattern,content) for item in items: if item[1] == ’2011-09-16’:continue if item[1] > day: #如果是30天內的帖子,保存post_list.append(’https://bbs.hupu.com’ + item[0]) else: #如果已經超過30天了,就直接返回return post_list return post_list
函數的傳參是鏈接首頁,在函數中修改頁碼,并繼續搜索。
從回帖中搜索演員名字:
接下來的步驟也是通過一個函數來解決。函數的傳參包括上一步中得到的鏈接數組,已經想要查詢的演員名字(這個功能可以進一步擴展,將演員名字也用列表的形式傳輸,同時上一步生成的字典也可以多一些)。
由于虎撲論壇會將一些得到認可的回帖擺在前端,即重復出現。如圖3所示:
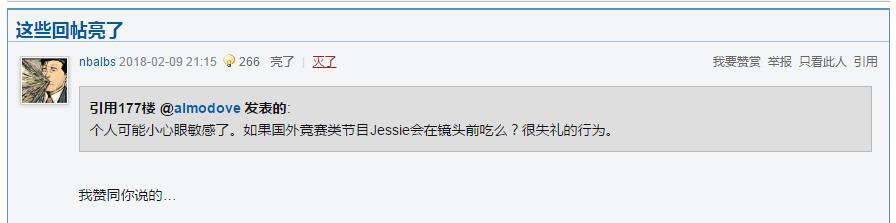
為了避免重復統計,將這些重復先去除,代碼如下:
if i == 0:index = content.find(’更多亮了的回帖’)if index >= 0: content = content[index:]else: index = content.find(’我要推薦’) content = content[index:]
去除的規則其實并不重要,因為每個論壇都有自己的格式,只要能搞清楚源代碼中是怎么寫的,剩下的操作就可以自己根據規則進行。
每個回帖格式大致如圖4,

用對應的正則表達式再去匹配,找到每個帖子每一個回帖的內容,在內容中搜索演員名字,即一開始的actor_1與actor_2,如果搜到,則在對應回帖日期下+1。
最終將兩位演員名字出現頻率返回,按日期記錄的字典由于是全局變量,不需要返回。
web_str = ’<span class='stime'>(.*?) .*?</span>.*?<tbody>[s]*<tr>[s]*<td>(.*?)<br />’ #找到回帖內容的正則 pattern = re.compile(web_str, re.S) items = re.findall(pattern,content) for item in items:#if ’<b>引用’ in item: #如果引用別人的回帖,則去除引用部分 #try: #item = item.split(’</blockquote>’)[1] #except: #print item #print item.decode(’utf-8’)if actor_1 in item[1]: actor1_dict[item[0]] += 1 actor_1_freq += 1if actor_2 in item[1]: actor2_dict[item[0]] += 1 actor_2_freq += 1
至此,我們就利用爬蟲知識,成功完成對論壇關鍵字的頻率搜索了。
這只是一個例子,關鍵字可以任意,這也不只是一個針對演員的誕生而寫的程序。將演員名字換成其他詞,就可以做到類似“您的年度關鍵字”這樣的結果,根據頻率大小來顯示文字大小。
以上就是本文的全部內容,希望對大家的學習有所幫助,也希望大家多多支持好吧啦網。
相關文章:
 網公網安備
網公網安備