使用python操作lmdb對數據讀取的實例
由于c++速度快,所以一般寫入數據我調用c++借口,而讀取數據使用c++也行,但有時候Python在某方面方便,所以通過使用python借口僅僅對lmdb文件讀取,處理數據是圖片
import lmdbimport numpy as npimport cv2lmdb_file = '/home/rui/demo'lmdb_env = lmdb.open(lmdb_file)lmdb_txn = lmdb_env.begin()lmdb_cursor = lmdb_txn.cursor()for key, value in lmdb_cursor: img = cv2.imdecode(np.fromstring(value, np.uint8), 3); cv2.imshow('demo', img) cv2.waitKey(0)
補充知識:Python解析lmdb格式mnist數據集
背景
HDF5和LMDB都是Cafffe中常用的數據庫。相對來說,HDF5的讀寫格式簡單;LMDB采用內存-映射文件(memory-mapped files),所以擁有非常好的I/O性能,而且對于大型數據庫來說,HDF5的文件常常整個寫入內存。
所以HDF5的文件大小就受限于內存大小,當然也可以通過文件分割來解決問題,但其I/O性能就不如LMDB的頁緩存(page cachiing)策略了。
MNIST手寫數字字符識別實驗在deep learning 中經常用到,這里使用Python來獲取lmdb格式MNIST數據集中的圖片并顯示出來
Python讀取LMDB
首先確認你安裝了lmdb和Caffe的python包(Caffe中的pycaffe)。
pip install lmdb
LMDB采用鍵值對的存儲格式,key就是字符形式的ID,value是Caffe中Datum類的序列化形式。
# -*- coding:utf-8 -*-import caffefrom caffe.proto import caffe_pb2import lmdbimport cv2 as cvenv = lmdb.open('mnist_train_lmdb', readonly=True) # 打開數據文件txn = env.begin() # 生成處理句柄cur = txn.cursor() # 生成迭代器指針datum = caffe_pb2.Datum() # caffe 定義的數據類型for key, value in cur: print(type(key), key) datum.ParseFromString(value) # 反序列化成datum對象 label = datum.label data = caffe.io.datum_to_array(datum) print data.shape print datum.channels image = data[0] # image = data.transpose(1, 2, 0) print(type(label)) cv.imshow(str(label), image) cv.waitKey(0)cv.destroyAllWindows()env.close()
運行結果:
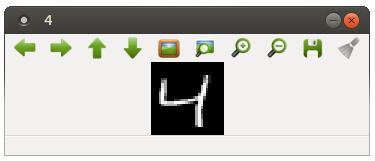

讀取LMDB數據庫中的Datum數據,這里再稍微介紹一下Datum的格式:channels:圖片的通道,彩色圖有3個通道,灰度圖只有1通道,當然也可以用通道數來表示其他意思,比如表示兩張圖片,每個通道一個單張的圖;height:圖片(即data)的高;width:圖片(即data)的寬;data:圖片的數據(像素值);label:圖片的label。(datum.channels, datum.height, datum.width)
以上這篇使用python操作lmdb對數據讀取的實例就是小編分享給大家的全部內容了,希望能給大家一個參考,也希望大家多多支持好吧啦網。
相關文章:

 網公網安備
網公網安備