python pdfkit 中文亂碼問題的解決方案
使用python pdfkit生成pdf文件中遇到中文亂碼問題
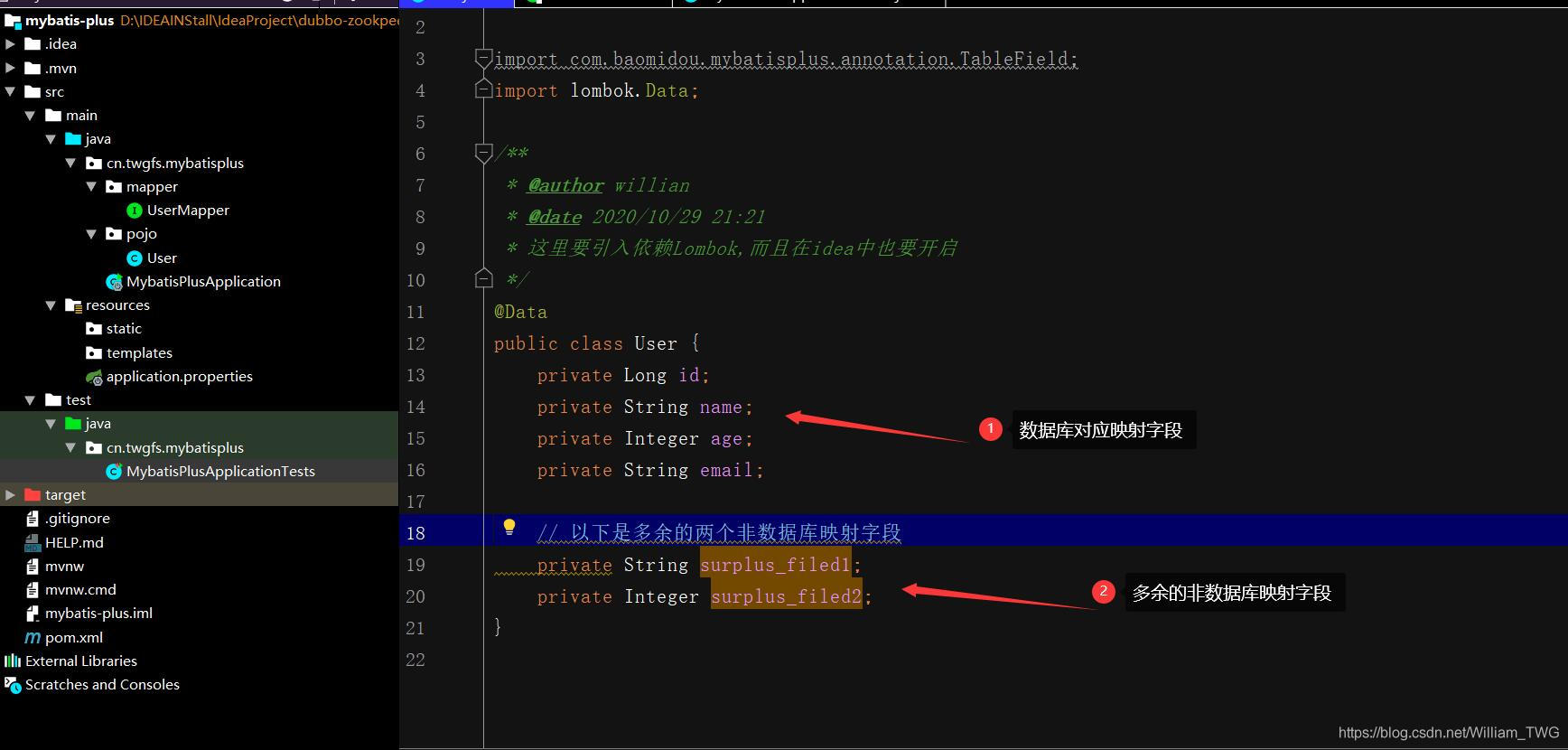
1.生成的文件名不能帶有中文字符
2.生成的pdf內容中文為亂碼
生成的文件名不能帶有中文字符解決方法:我暫時想到的處理方式是先生成英文文件名,再將這個文件重命名為中文的文件名
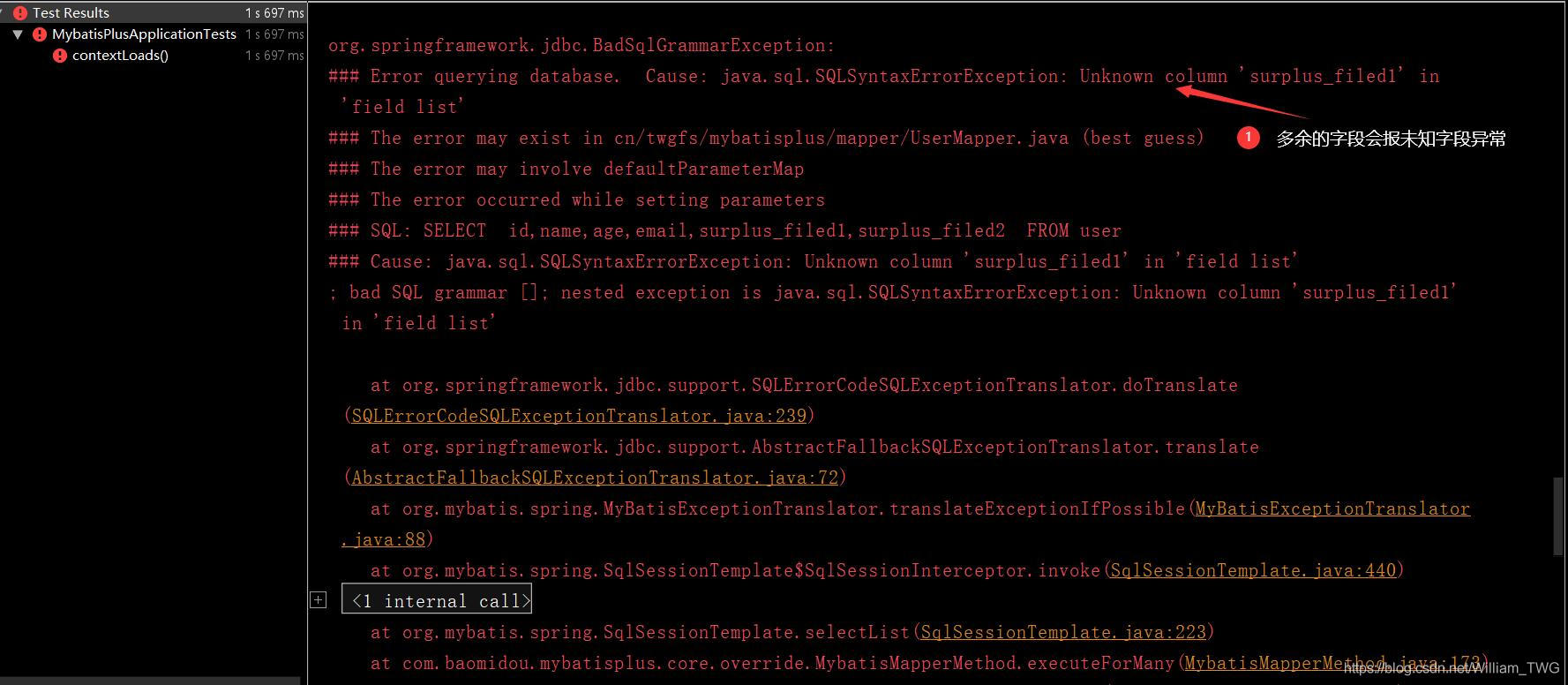
#coding=utf8import osimport pdfkitfrom uuid import uuid1ret = ’<html><head><meta charset='UTF-8'></head><body><h1>測試pdf內容部分</h1></body></html>’.decode(’utf8’)file_name = str(uuid1())pdfkit.from_string(ret, file_name) # file_name不能帶有中文 如果有會報錯file_name_new = ’測試.pdf’os.rename(file_name, file_name_new)生成的pdf內容中文為亂碼原因1:
因為pdfkit生成pdf功能其實調用的是webkit的子模塊wkhtmltopdf(通過命令行方式),所以pdfkit生成中文亂碼其實是wkhtmltopdf中文亂碼導致的;而wkhtmltopdf中文亂碼是因為系統中不存在中文字體導致的
解決方法:在系統中添加中文字體
我的本地電腦是ubuntu14.04的字體文件保存在/usr/share/fonts下(包含了中文字體文件具體哪一個我也不知道汗。),我的服務器是redhat系統(沒有中文字體),所以在我的電腦上操作如下:
cd /usr/share/fontszip -r fonts.zip ./*scp fonts.zip 服務器用戶名@服務器ip:/usr/share/fonts
在服務器上操作如下:
cd /usr/share/fontsunzip fonts.zipfc-cache -fvfc-list # 查看新添加的字體
你需要找一臺有安裝了中文字體的電腦復制一份字體文件(就是/usr/share/fonts下的文件),然后如我以上操作就可以了。
原因2:需要在html的字符集設置為utf8
<head><meta charset='UTF-8'></head>
補充:python寫入html文件中文亂碼-解決辦法
使用open函數將爬蟲爬取的html寫入文件,有時候在控制臺不會亂碼,但是寫入文件的html中的中文是亂碼的
案例分析看下面一段代碼:
# 爬蟲未使用cookiefrom urllib import requestif __name__ == ’__main__’: url = 'http://www.renren.com/967487029/profile' rsp = request.urlopen(url) html = rsp.read().decode() with open('rsp.html','w')as f: # 將爬取的頁面 print(html) f.write(html)
看似沒有問題,并且在控制臺輸出的html也不會出現中文亂碼,但是創建的html文件中
使用open方法的一個參數,名為encoding=” “,加入encoding=”utf-8”即可
# 爬蟲未使用cookiefrom urllib import requestif __name__ == ’__main__’: url = 'http://www.renren.com/967487029/profile' rsp = request.urlopen(url) html = rsp.read().decode() with open('rsp.html','w',encoding='utf-8')as f: # 將爬取的頁面 print(html) f.write(html)
運行結果
以上為個人經驗,希望能給大家一個參考,也希望大家多多支持好吧啦網。如有錯誤或未考慮完全的地方,望不吝賜教。
相關文章:
 網公網安備
網公網安備