python利用K-Means算法實現對數據的聚類案例詳解
目的是為了檢測出采集數據中的異常值。所以很明確,這種情況下的簇為2:正常數據和異常數據兩大類
1、安裝相應的庫import matplotlib.pyplot as plt # 用于可視化from sklearn.cluster import KMeans # 用于聚類import pandas as pd # 用于讀取文件2、實現聚類2.1 讀取數據并可視化
# 讀取本地數據文件df = pd.read_excel('../data/output3.xls', header=0)
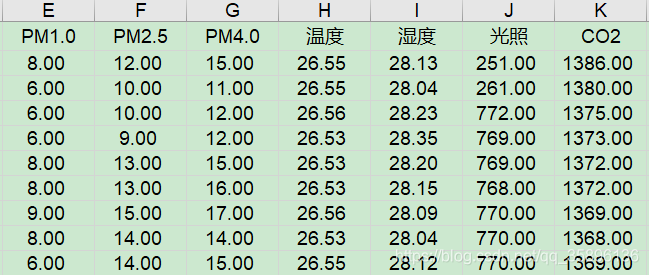
本次實驗選擇溫度和CO2作為二維數據,其中溫度含有異常數據。
plt.scatter(df['光照'], df['CO2'], linewidths=1, alpha=0.8)plt.rcParams[’font.sans-serif’] = [’SimHei’] # 用來正常顯示中文標簽vplt.xlabel('光照')plt.ylabel('CO2')plt.grid(color='#95a5a6', linestyle='--', linewidth=1, alpha=0.4)plt.show()
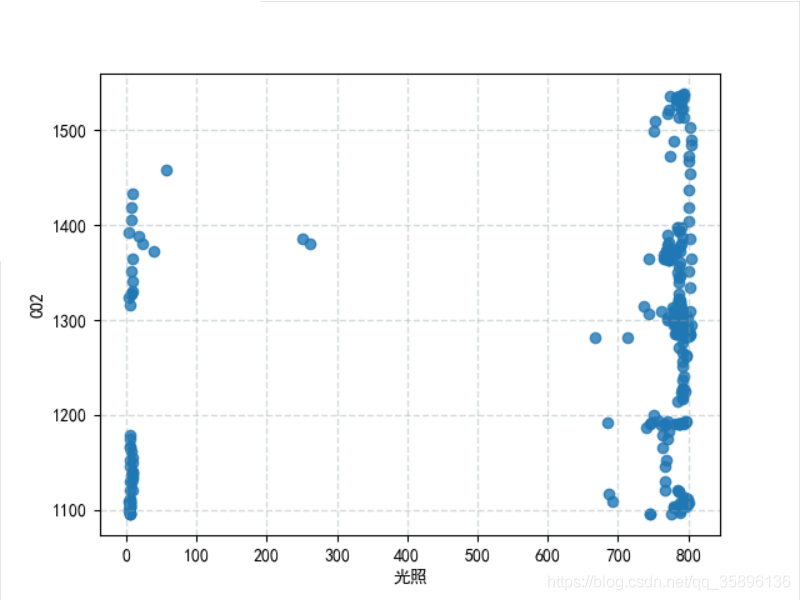
設置規定要聚的類別個數為2
data = df[['光照','CO2']] # 從原始數據中選擇該兩項estimator = KMeans(n_clusters=2) # 構造聚類器estimator.fit(data) # 將數據帶入聚類模型
獲取聚類中心的值和聚類標簽
label_pred = estimator.labels_ # 獲取聚類標簽centers_ = estimator.cluster_centers_ # 獲取聚類中心
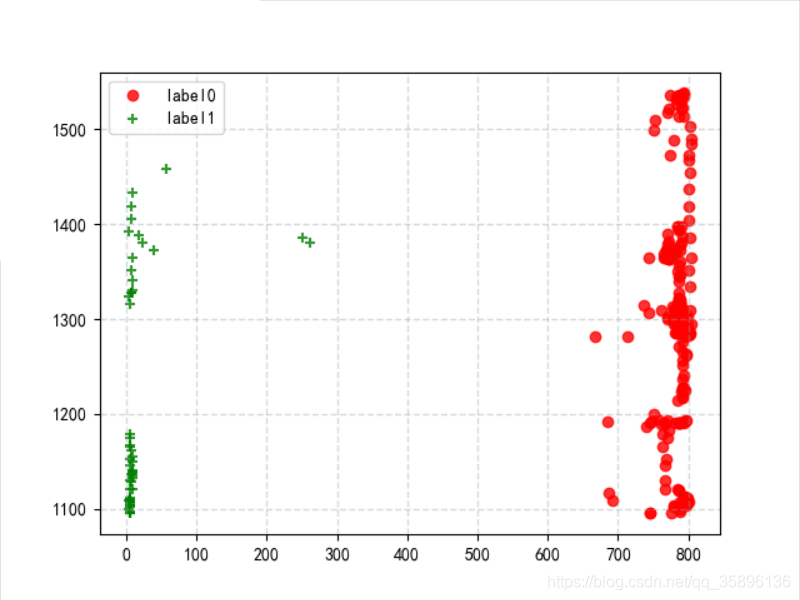
將聚類后的 label0 和 label1 的數據進行輸出
x0 = data[label_pred == 0]x1 = data[label_pred == 1]plt.scatter(x0['光照'], x0['CO2'],c='red', linewidths=1, alpha=0.8,marker=’o’, label=’label0’)plt.scatter(x1['光照'], x1['CO2'],c='green', linewidths=1, alpha=0.8,marker=’+’, label=’label1’)plt.grid(c='#95a5a6', linestyle='--', linewidth=1, alpha=0.4)plt.legend()plt.show()
附上全部代碼
import matplotlib.pyplot as pltfrom sklearn.cluster import KMeansimport pandas as pddf = pd.read_excel('../data/output3.xls', header=0)plt.scatter(df['光照'], df['CO2'], linewidths=1, alpha=0.8)plt.rcParams[’font.sans-serif’] = [’SimHei’] # 用來正常顯示中文標簽vplt.xlabel('光照')plt.ylabel('CO2')plt.grid(color='#95a5a6', linestyle='--', linewidth=1, alpha=0.4)plt.show()data = df[['光照','CO2']]estimator = KMeans(n_clusters=2) # 構造聚類器estimator.fit(data) # 聚類label_pred = estimator.labels_ # 獲取聚類標簽centers_ = estimator.cluster_centers_ # 獲取聚類結果# print('聚類標簽',label_pred)# print('聚類結果',centers_)# predict = estimator.predict([[787.75862069, 1505]]) # 測試新數據聚類結果# print(predict)x0 = data[label_pred == 0]x1 = data[label_pred == 1]plt.scatter(x0['光照'], x0['CO2'],c='red', linewidths=1, alpha=0.8,marker=’o’, label=’label0’)plt.scatter(x1['光照'], x1['CO2'],c='green', linewidths=1, alpha=0.8,marker=’+’, label=’label1’)plt.grid(c='#95a5a6', linestyle='--', linewidth=1, alpha=0.4)plt.legend()plt.show()
到此這篇關于python利用K-Means算法實現對數據的聚類的文章就介紹到這了,更多相關python K-Means算法數據的聚類內容請搜索好吧啦網以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持好吧啦網!
相關文章:
 網公網安備
網公網安備