編碼 - Python 3.6中 ’utf-8’ codec can’t decode byte invalid start byte?
問題描述
Python 3.6中,網頁信息解析失敗,試了很多種編碼,查看網頁的編碼方式也是utf-8。錯誤信息:’utf-8’ codec can’t decode byte 0x8b in position 1: invalid start byte?還有就是第一個print終端里打印出來的unicode內容是[b’x1fx8bx08x00x...]這種格式的,之前也有過這種情況,一個print打2個變量,就是b’x, 如果分來2行打又變回了漢字。是因為什么原因呢?
# -*- coding: utf-8 -*-import json , sqlite3import urllib.requesturl = (’http://wthrcdn.etouch.cn/weather_mini?city=%E4%B8%8A%E6%B5%B7’)resp = urllib.request.urlopen(url)content = resp.read()print(content)print(type(content))print(content.decode(’utf-8’))
問題解答
回答1: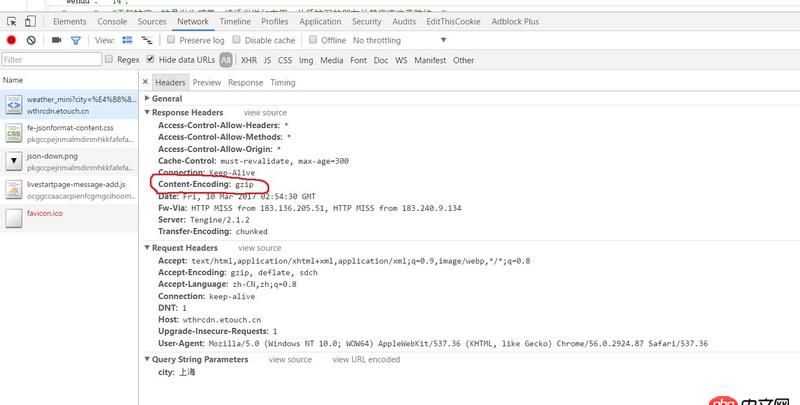
看了一下網站返回的是gzip壓縮過的數據,所以要進行解碼
# coding=utf-8from io import BytesIOimport gzipimport urllib.requesturl = (’http://wthrcdn.etouch.cn/weather_mini?city=%E4%B8%8A%E6%B5%B7’)resp = urllib.request.urlopen(url)content = resp.read() # content是壓縮過的數據buff = BytesIO(content) # 把content轉為文件對象f = gzip.GzipFile(fileobj=buff)res = f.read().decode(’utf-8’)print(res)
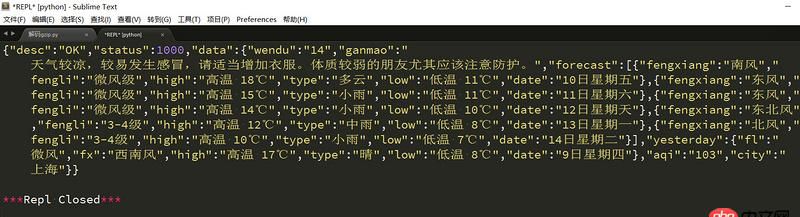
requests不好用嗎?
回答3:
建議用requeset,代碼如下:
import requestsr = requests.get(’http://wthrcdn.etouch.cn/weather_mini?city=%E4%B8%8A%E6%B5%B7’)print(r.text)回答4:
不是字符編碼問題, 你看看你請求的 Respont headers
Status Code: 200 OK Access-Control-Allow-Headers: * Access-Control-Allow-Methods: * Access-Control-Allow-Origin: * Cache-Control: must-revalidate, max-age=300 Connection: Keep-Alive Content-Encoding: gzip Content-Length: 443 Date: Fri, 10 Mar 2017 03:20:46 GMT Fw-Cache-Status: hit Fw-Via: HTTP MISS from 58.59.19.99, DISK HIT from 183.131.161.27 Server: Tengine/2.1.2
是gzip, 如果用標準庫的東西, 還需要把gzip 給解開
相關文章:
1. python的文件讀寫問題?2. javascript - h5上的手機號默認沒有識別3. mysql里的大表用mycat做水平拆分,是不是要先手動分好,再配置mycat4. javascript - 圖片鏈接請求一直是pending狀態(tài),導致頁面崩潰,怎么解決?5. javascript - 關于圣杯布局的一點疑惑6. python - 獲取到的數據生成新的mysql表7. javascript - 請問 chrome 為什么會重復加載圖片資源?8. window下mysql中文亂碼怎么解決??9. javascript - jquery hide()方法無效10. 怎么用css截取字符?

 網公網安備
網公網安備