文章詳情頁
python - 使用scrapy的時候,循環為什么只能獲取第一頁的
瀏覽:84日期:2022-07-04 18:26:20
問題描述
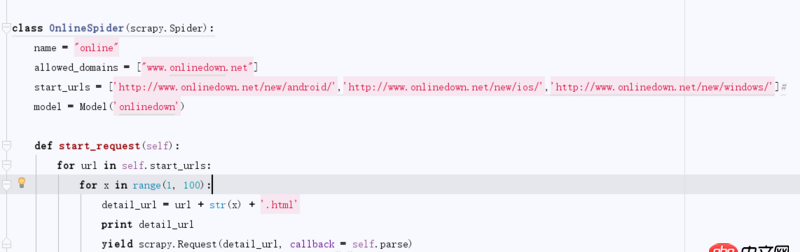
class OnlineSpider(scrapy.Spider):name = 'online'allowed_domains = ['www.onlinedown.net']start_urls = [’http://www.onlinedown.net/new/android/’,’http://www.onlinedown.net/new/ios/’,’http://www.onlinedown.net/new/windows/’]#model = Model(’onlinedown’)def start_request(self): for url in self.start_urls:for x in range(1, 100): detail_url = url + str(x) + ’.html’ print detail_url yield scrapy.Request(detail_url, callback = self.parse)
每頁是35條,結果是105條。這是為什么呢。
問題解答
回答1:parse函數怎么寫的啊
回答2:你的parse方法呢?
排行榜

 網公網安備
網公網安備