mysql優化 - mysql count(id)查詢速度如何優化?
問題描述
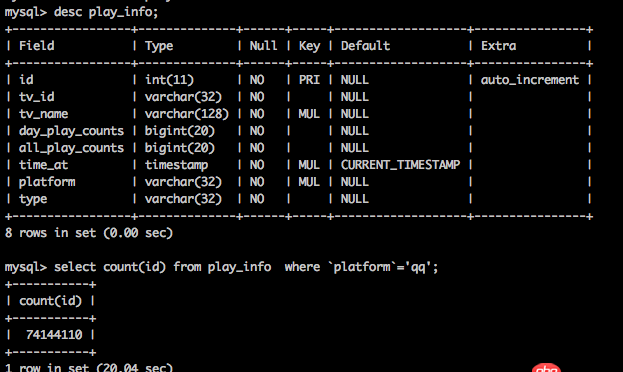
表結構如圖所示。
目前數據量是8000W行。
請問有什么優化的方法和思路嗎?
問題解答
回答1:count(*)不會統計每一列的值(不管是否為null),而是直接統計行數,效率要高些;
另外也可以用排除法,比如platform是qq的數據很多,可以用總的數據減掉platform=other的數據;
從業務上來考慮,精確值獲取成本很高,然而近似值成本較低,如果要求不嚴格,可以用近似值代替;
另外也可以考慮用redis等“內存數據庫”來維護這種獲取耗時的數據;
回答2:1.如果當我遇到這樣的問題的話,我的解決辦法是新建一個表,例如playfrom_count來統計. 框架中如果用after_insert以及after_delete這樣的方法更好,如果沒有的話就自己寫一個.2.如果這樣的查詢業務量不是很大的話,或者不是很精確的話,可以做一個任務去跑.每隔一段時間更新一次.3.無論你是innodb還是myisam,因為你添加了where所以都會對全表進行掃描.所以可以通過添加主鍵來增加檢索速度.
回答3:方案1. 對platform建立分區表方案2. 按platform分表方案3. 對platform建單獨索引,不過考慮你platform的值集應該不會很大,這樣做索引不合適
回答4:這個問題在經典的關系型數據庫都會遇到,通用的解決方法是去訪問系統表,里面有每一個表的數據行數,速度比你 COUNT(*) 快無數倍。
回答5:升級下機器吧,怎么簡單的count都要20s,雖然有很多辦法比如分區表,但是感覺投入得不償失.
回答6:建議先考慮一下業務場景的需求,單純從技術方面考慮的解決方案成本過高,很多時候基本上實施不了。可能的解決方案有:1、分表:按照platform分為多個表,存儲引擎為MyISAM,查詢語句改為count(*),MyISAM會保存表的總行數,因此查詢效率很有極大的提升。需要考慮分表對系統改造的工作量、MyISAM不支持事務是否能滿足系統要求。
2、建立冗余表或字段,把需要匯總的數據在變更時重新計算,需要考慮大量的更新操作是否加大系統的負載。
3、如果對查詢結果不要求時完全精確的,可以定時計算結果并保存起來,查詢的時候不在直接查詢原表。
回答7:這種情況下可以按照月或者季度等分為多個統計表,比如你800萬數據,新建一張表,每一行代表一個月的總記錄。這樣再統計就會快得多得多。
相關文章:
1. docker-compose中volumes的問題2. php - 想要遠程推送emjio ios端怎么搞 需要怎么配合3. vim - docker中新的ubuntu12.04鏡像,運行vi提示,找不到命名.4. python 多進程 或者 多線程下如何高效的同步數據?5. android - 添加multidex后在部分機型上產生anr的問題,該如何解決6. angular.js - node.js中下載的angulae無法引入7. java - Hibernate查詢的數據是存放在session中嗎?8. node.js - 問個問題 Uncaught (in promise)9. python爬蟲字符編碼錯誤問題10. angular.js - Angular 刷新頁面問題
 網公網安備
網公網安備